Tutti i nostri messaggi di Gmail sono stati letti. E non dai computer di Google, anzi nemmeno da Google, ma da dipendenti in carne ed ossa di applicazioni di terze parti.
E’ la bomba lanciata da uno speciale del Wall Street Journal, che ha rivelato l’ennesimo scandalo della privacy a carico del re dei motori di ricerca. Gli sviluppatori di applicazioni di terze parti costruiscono in continuazione servizi in collaborazione con Gmail per aiutarci a individuare occasioni sull’acquisto dei prodotti o per organizzare dei viaggi.
Ebbene, alcuni di questi sviluppatori hanno potuto leggere personalmente le nostre email private e hanno permesso che le leggessero anche i loro dipendenti, secondo il report pubblicato dal Wall Street Journal.
Privacy su Gmail. Ecco i dipendenti che hanno letto personalmente le nostre mail
Il quotidiano americano riporta in particolare due casi. Il primo si chiama Return Path, un’applicazione che analizza le mail in entrata degli utenti, e raccoglie dati per gli investitori pubblicitari. Return Path avrebbe fatto leggere ai suoi impiegati circa 8000 email degli utenti Gmail, scritte nei due anni scorsi, per sviluppare il software necessario al servizio.
L’altra app si chiama Edison e aiuta gli utenti a gestire i loro messaggi email: anche in questo caso i dipendenti avrebbero letto migliaia di messaggi per sviluppare la funzionalità “Smart Reply”.
Nell’industria dello sviluppo dei software non è strano che i produttori di applicazioni abbiano accesso a questo tipo di dati. Entrambe le applicazioni hanno ottenuto il consenso direttamente dagli utenti e questa pratica è prevista dagli accordi registrati al momento dell’utilizzo di Gmail. Google inoltre chiede agli utenti specifici permessi quando si parla di integrazione con applicazioni di terze parti.
Per esempio dopo il download di un’applicazione, Gmail è solita visualizzare un box in sovraimpressione chiedendo il permesso di leggere, inviare, cancellare e gestire le email attraverso l’app.
Ma la novità è che gli sviluppatori di terze parti e specialmente i loro dipendenti hanno potuto leggere personalmente le mail, e tutto questo quando, l’anno scorso, Google aveva annunciato di aver smesso di scansire le mail alla ricerca di informazioni utili agli investitori pubblicitari per targettizzare negli annunci.
Le applicazioni di terze parti che collaborano con Google avrebbero fatto leggere ai loro dipendenti le nostre mail. Ecco come e perchè lo hanno fatto
Sia Return Path che Edison si sono difesi con dei comunicati ufficiali. “Come chiunque programmatore di software sa, sono gli esseri umani a inventare i software, e l’intelligenza artificiale deriva dall’intelligenza umana. In ogni momento i nostri ingegneri ed esperti di dati leggono personalmente le mail degli utenti, ma eseguiamo degli stretti controlli per verificare chi ha accesso ai dati e supervisioniamo tutto il processo.”
Anche Edison fa quadrato: “La nostra applicazione per la gestione delle mail è stata creata dei nostri ingegneri che durante la fase dello sviluppo hanno potuto leggere una piccola parte casuale di messaggi da cui abbiamo epurato le singole identità. Questo metodo è stato utilizzato per lo sviluppo della funzionalità Smart Reply, che è stata prodotta ormai diverso tempo fa. Abbiamo comunque superato questa pratica ed eliminato tutti i dati sensibili per rimanere aderenti ai più alti standard possibili di privacy e sicurezza.”
La difesa di Google: “Non avete capito. Noi non leggiamo le mail”
Google ha risposto dopo alcuni giorni al report del Wall Street Journal: in un post sul suo blog ufficiale, Google ha spiegato come lavora assieme agli sviluppatori esterni. Il gigante dei motori di ricerca ha assicurato che le applicazioni di terze parti ottengono solamente dati aggregati, i quali vengono utilizzati solo ed esclusivamente per lo sviluppo del servizio. “La pratica dell’analisi automatica delle mail – si legge nel post di Google – è stata mal comunicata ed è passato il concetto che “Google legge le vostre email”. Per essere assolutamente chiari: nessuno in Google legge il contenuto dei messaggi Gmail, eccetto alcuni casi estremamente specifici dove ci è stato chiesto e accordato il consenso o per motivi di sicurezza come per esempio indagini su vulnerabilità o abusi.”
Privacy su Google e Gmail. Ecco perchè non dovremmo lamentarci
Di fronte a questo ennesimo caso sulla privacy dovremmo preoccuparci? e dovremmo arrabbiarci? Sicuramente abbiamo il diritto di farlo, ma tecnicamente parlando è difficile avere ragione.
Probabilmente nella stragrande maggioranza dei casi abbiamo dato il nostro consenso accettando frettolosamente e senza leggere le autorizzazioni richieste dal primo servizio integrato su Gmail che ci è stato proposto.
Dunque, come al solito, rinchiusi in un mondo digitale fin troppo veloce, abbiamo firmato sommariamente ma volontariamente il permesso di entrare nella nostra privacy.
Tuttavia bisogna considerare che le difese proposte dalle varie compagnie sono sostanzialmente vere. Ad esempio, la Return Path deve analizzare circa 100 milioni di email al giorno. È ovvio che questo debba essere fatto da dei computer, ma questi vanno istruiti e quando queste aziende spiegano che è necessario un insegnamento da parte di esseri umani, stanno effettivamente dicendo la verità.
Un altro esempio, sempre della Return Path, riguarda un problema che si è presentato durante lo sviluppo del loro servizio nel 2016. L’algoritmo etichettava per errore diverse email personali come commerciali. E questo significa che per andare avanti con lo sviluppo sono stati costretti ad utilizzare una intelligenza umana per correggere il tiro dei computer.
Se vi può rassicurare, in ambito di programmazione i dati personali contano abbastanza poco e dunque è estremamente probabile che i dipendenti che hanno letto le mail non abbiano nemmeno potuto leggere i dati sensibili, indirizzi e numeri di telefono, principalmente perché non gli interessa.
Il risultato, comunque, si esprime in termini di un servizio online per il quale non dobbiamo pagare nulla. E ci sono anche delle condizioni contrattuali da rispettare. Presso la Edison, ad esempio, gli ingegneri che si occupano di gestire l’intelligenza artificiale firmano un contratto che gli impedisce di diffondere sotto qualunque forma quello che hanno letto.
Insomma può dare fastidio, ma siamo stati proprio noi a dargli il permesso e comunque la possibilità che i dipendenti delle aziende si siano divertiti a scoprire i fatti nostri… è piuttosto remota.
Facebook ascolta segretamente le nostre conversazioni? Capita spesso che alcune persone riferiscano di leggere degli annunci pubblicitari relativi e prodotti di cui hanno appena parlato a voce con gli amici e di essere stati in qualche modo incuriositi dalla vicenda.
Inizia come un sospetto, a volte ci si pensa paranoici, in altri casi si chiede consiglio o conferma ai propri amici. Vi spiegheremo come e perché non siete matti a pensare tutto ciò, ma probabilmente l’ipotesi che Facebook ascolti tutti noi non è verosimile, e non certo per la bontà del social network ma per evidenti motivi tecnici.
Facebook ascolta le nostre conversazioni? studiamo il fenomeno
Innanzitutto chiariamo il fatto che non siete malati di mente. Nel corso degli anni diverse persone hanno manifestato il sospetto che le loro conversazioni venissero registrate o per lo meno ascoltate anche a smartphone spento e che queste si siano tradotte in annunci pubblicitari mirati.
E questa ipotesi ha preso talmente tanto piede che negli Stati Uniti alcune puntate di popolari show televisivi sono state dedicate all’argomento. Nel 2016 un professore di telecomunicazioni iniziò a parlare di cibo per gatti durante una puntata, tirò fuori lo smartphone facendo partire l’applicazione di Facebook e dimostrò al pubblico come fossero comparsi magicamente degli annunci relativi al cibo per animali.
Effettivamente questa teoria, in un mondo dominato dai computer, può sembrare perlomeno verosimile e la questione ha preso talmente tanto piede che il congresso americano ha ufficialmente chiesto direttamente al fondatore di Facebook chiarimenti sulla vicenda.
In quell’occasione Zuckerberg ha parlato di una teoria cospirazionale e ha negato in maniera categorica che Facebook ascolti le conversazioni anche ad applicazione chiusa per targettizzare gli annunci.
Il fondatore di Facebook ha spiegato che le persone vedono una quantità enorme di video e di post attraverso il feed di Facebook, molto spesso si dimenticano dei contenuti che hanno letto e questi possono tornare di volta in volta nelle conversazioni. Una specie di auto suggestione che li porta a credere di essere spiati.
Mark Zuckerberg, il fondatore di Facebook, durante gli interrogatori del Senato americano: “Facebook non ascolta in nessuna occasione le conversazioni degli utenti. Si tratta di una suggestione”.
Volendo fare un’analisi dobbiamo dire che l’ipotesi di un ascolto di massa da parte di Facebook non è verosimile. Ma non perché nutriamo fiducia nella gestione della privacy di Facebook. È completamente fuori discussione.
Nel 2010 Facebook cambiò le impostazioni di privacy di tutti i suoi utenti senza chiedere permesso a nessuno. Nel 2007 le persone iniziarono a poter vedere gli acquisti dei loro amici su altri siti attraverso uno strumento apposito, che portò ad una denuncia collettiva, una class-action da 9,5 milioni di dollari.
Riteniamo che Facebook non vi stia registrando per altri motivi, che sono sostanzialmente dei limiti tecnici ed economici.
Facebook non ci ascolta. Perchè nessuno lo ha scoperto
Il primo motivo è che nessuno ha mai rivelato niente sulla questione. Quando Facebook è accusata di qualche cosa e questa cosa in fondo è vera, tende a dare delle informazioni generali, ad appoggiarsi al fatto che si tratta di dati aggregati o che nessun elemento sensibile viene condiviso. Mentre in questo caso la posizione di Facebook è stata monolitica.
E Facebook è piena di ex impiegati che cercano di rivelarne i segreti per qualsiasi motivo, dalla vendetta ai soldi. Ogni tipo di violazione della privacy tende a essere scoperta, diffusa e rivelata e il fatto che durante gli anni nessuno sia mai riuscito a coglierli in castagna potrebbe confermare che non c’è nulla di concreto da comunicare al mondo.
Perchè sarebbe molto difficile
In secondo luogo ci sono dei limiti tecnici. La tecnologia per il riconoscimento vocale è piuttosto complessa. Al momento attuale gli unici capaci di farla bene sono Google e Facebook. Apple ci prova con Siri ma con risultati che non sono sempre convincenti.
Ancora di più se il riconoscimento della voce non viene fatto vicino alla sorgente audio ma a distanza, quando il telefono è in tasca o nella borsa. A livello tecnico sarebbe una grande sfida anche per questo tipo di piattaforme.
Inoltre per farlo Facebook dovrebbe violare i termini del servizio di Apple e di Google, sfruttare una vulnerabilità nel loro codice e trovare un modo di ascoltare anche quando le applicazioni non sono aperte.
Sarebbe capacissimo di spiarci. Ma al momento un riconoscimento vocale così complesso costerebbe troppo e non porterebbe a Facebook altrettanto vantaggio economico
Inoltre le informazioni devono essere vagliate da qualcuno. Finché si tratta di qualche cosa di scritto, Facebook potrebbe appoggiarsi a dei computer, ma una conversazione telefonica, o anche tra persone dovrebbe essere in qualche modo interpretata da collaboratori reali che possano percepirne il senso.
Contando che gli utenti di Facebook sfiorano gli 1,3 miliardi, appare difficile che il social network abbia la forza per decifrare ed estrapolare il senso di tutte le conversazioni di una tale mole di persone.
E non ha affatto bisogno di altri dati
L’altro grande motivo per cui è difficile che Facebook ascolti le nostre conversazioni è che la spesa non vale la resa.
Un investimento gigantesco per una tecnologia del genere che cosa gli porterebbe? Dei dati in più?
Facebook non ha assolutamente problemi di dati.
Facebook sa, già solo attraverso l’utilizzo della sua piattaforma, la nostra posizione geografica e ci può tracciare in ogni momento. Può sapere dove andiamo su internet, quali prodotti compriamo o stiamo per comprare. Vede le nostre immagini sia su Facebook che su Instagram e chi vive con noi. Può tracciare le parole chiave che utilizziamo su WhatsApp o su Messenger, conoscere tutti i numeri di telefono dei nostri amici e dei nostri colleghi di lavoro e può correlarli.
Facebook può conoscere i membri della nostra famiglia, capire dalle ricerche se stiamo per rivelare a tutti di essere gay, identificare la nostra religione e le tendenze politiche e soprattutto è in grado di predire cosa stiamo per guardare, leggere o comprare nel prossimo futuro. La compagnia è in grado di tracciare addirittura gli utenti che non utilizzano Facebook, proprio analizzando i buchi di dati nel suo database e vende queste probabili identità agli inserzionisti pubblicitari.
Insomma la quantità di dati, la loro correlazione e la loro qualità sono già enormi. Per cui un investimento multimilionario in una tecnologia del genere non accrescerebbe che di pochissimo il valore delle informazioni.
Come impedire a Facebook di ascoltare le nostre conversazioni (se ancora ne siete convinti)
Comunque per chi fosse frustrato dal tracciamento che questo social network riesce ad esercitare sui suoi utenti, vi lasciamo con alcune istruzioni che possono limitare l’invasività di questa piattaforma.
Per ogni opzioni clicca su “Off” o “No” per limitare il modo con cui Facebook personalizza gli annunci. (Se disattivi anche l’intera sezione “I tuoi interessi”, potrebbero essere necessari diversi minuti).
Installa un blocco annunci. Sul tuo computer, prova Adblock Plus o uBlock. Sul telefono, prova 1Blockero Purifysu iOS e AdblockBrowser su Android. Questi non possono bloccare i contenuti nell’app di Facebook, ma possono bloccare i tracker di Facebook sul tuo normale browser mobile.
Installa Facebook Disconnect (per Chromeo per Firefox), che impedisce a Facebook di vedere cosa fai su altri siti web.
Se volete raggiungere la paranoia, potete bloccare l’uso del microfono nell’app di Facebook e la videocamera su iOS e Android
Su iPhone (iOS 9)
Vai all’app Impostazioni
Scorri fino a Facebook,
Tocca “Impostazioni“
Disattiva il cursore per Microfono (il cursore dovrebbe essere grigio anziché verde)
Wikipedia ci va giù pesante: la più celebre enciclopedia online si blocca completamente per protestare contro la riforma UE della legge sul copyright. Non un invito o un appello, ma una azione di forza d’iniziativa tutta italiana per proteggere la libertà del web. Ma ad averne un danno sono stati, per ora, gli utenti italiani.
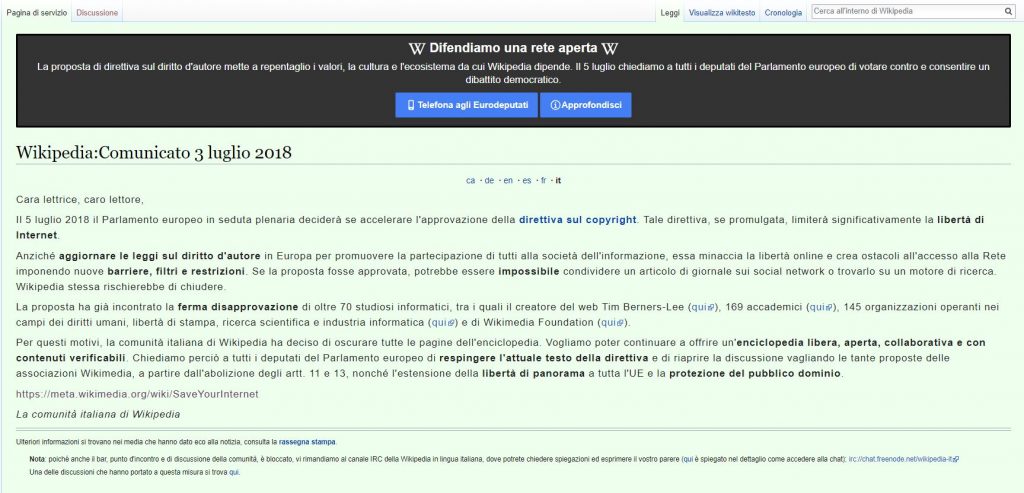
Così appariva stamattina la pagina principale di Wikipedia Italia. Per alcune frazioni di secondo si poteva intravedere il suo regolare contenuto, ma in realtà la home page era dominata da una pagina di blocco. “Difendiamo una rete aperta” si legge, e ancora: “La proposta di direttiva sul Diritto d’autore mette a repentaglio i valori, la cultura e l’ecosistema da cui Wikipedia dipende. Il 5 luglio chiediamo a tutti i deputati del Parlamento Europeo di votare contro e consentire un dibattito democratico“.
La home page di Wikipedia. Un blocco completo per protestare contro la riforma UE del copyright. E un tasto che invita a telefonare direttamente agli eurodeputati
Wikipedia Italia si blocca: la protesta contro la riforma UE sul copyright
La legge a cui fa riferimento Wikipedia è la riforma del copyright recentemente approvata dal Parlamento Europeo, aspramente contestata in quanto potrebbe causare danni ai piccoli quotidiani online e imporre un filtro ai contenuti caricati dagli utenti, il che si teme possa sfociare in una censura digitale.
Il messaggio rivolto agli utenti recita:
[miptheme_quote author=”” style=”text-center”]Cara lettrice, caro lettore, Il 5 luglio 2018 il Parlamento europeo in seduta plenaria deciderà se accelerare l’approvazione della direttiva sul copyright. Tale direttiva, se promulgata, limiterà significativamente la libertà di Internet.
Anziché aggiornare le leggi sul diritto d’autore in Europa per promuovere la partecipazione di tutti alla società dell’informazione, essa minaccia la libertà online e crea ostacoli all’accesso alla Rete imponendo nuove barriere, filtri e restrizioni. Se la proposta fosse approvata, potrebbe essere impossibile condividere un articolo di giornale sui social network o trovarlo su un motore di ricerca. Wikipedia stessa rischierebbe di chiudere.
La proposta ha già incontrato la ferma disapprovazione di oltre 70 studiosi informatici, tra i quali il creatore del web Tim Berners-Lee, 169 accademici, 145 organizzazioni operanti nei campi dei diritti umani, libertà di stampa, ricerca scientifica e industria informatica e di Wikimedia Foundation.
Per questi motivi, la comunità italiana di Wikipedia ha deciso di oscurare tutte le pagine dell’enciclopedia. Vogliamo poter continuare a offrire un’enciclopedia libera, aperta, collaborativa e con contenuti verificabili.
Chiediamo perciò a tutti i deputati del Parlamento europeo di respingere l’attuale testo della direttiva e di riaprire la discussione vagliando le tante proposte delle associazioni Wikimedia, a partire dall’abolizione degli artt. 11 e 13, nonché l’estensione della libertà di panorama a tutta l’UE e la protezione del pubblico dominio.
https://meta.wikimedia.org/wiki/SaveYourInternet La comunità italiana di Wikipedia[/miptheme_quote]
Ma Wikipedia non si limita a lamentarsi, ma anche a passare all’azione. Sulla pagina si trovano due tasti. Il primo invita a telefonare ad un Eurodeputato: cliccando si arriva al sito changecopyright.org, realizzato dalla fondazione Mozilla, la stessa che produce il browser Firefox. Il meccanismo prevede che l’utente inserisca il suo numero di cellulare e attenda di essere richiamato.
In collegamento dall’altro capo del telefono un europarlamentare a cui rivolgere la propria segnalazione. Wikipedia fornisce anche un testo precompilato da recitare e personalizzabile, per facilitare il compito.
[miptheme_quote author=”” style=”text-center”]“Buongiorno, mi chiamo [nome e cognome] e chiamo da [città, nazione].” “Vorrei discutere della proposta di riforma del copyright.
Sono un [tecnologo, artista, scienziato, giornalista, bibliotecario, ecc.] e ritengo che la posizione del Parlamento europeo relativamente alla proposta di riforma del copyright danneggi seriamente l’innovazione e la creatività nell’Unione Europea.”
“La invito pertanto a opporsi all’approvazione dell’articolo 13. Il futuro dell’innovazione in Europa dipende da Lei.”
“La ringrazio infinitamente per il tempo e l’impegno che sta dedicando a migliorare la legge sul diritto d’autore nel Mercato unico digitale europeo.”[/miptheme_quote]
In alternativa, cliccando su un secondo tasto “Approfondisci” si possono leggere spiegazioni dettagliate sulla riforma e viene proposto il link diretto ai profili social degli europarlamentari, per inviargli ulteriori messaggi. Divisi per nome e cognome, nazionalità e partito europeo di appartenenza, è possibile scrivere ai parlamentari europei, uno per uno.
Le spiegazioni del portavoce. L’UE: “Wikipedia non è nel mirino”.
Si tratta di una azione di forza, tra l’altro di iniziativa completamente italiana. “Ci dispiace per il disagio, soprattutto per gli studenti che in questi giorni affrontano la maturità – ha spiegato Maurizio Codogno, portavoce di WikiMedia Italia – ma non potevamo aspettare. Quello che oggi è un oscuramento voluto, presto potrebbe essere obbligato”. Secondo Codogno, se la legge diventasse realtà “solamente per citare una pubblicazione usata come fonte dovremmo richiedere il benestare dell’editore, che peraltro potrebbe avanzare pretese economiche… e per i siti che ospitano materiale caricato dagli utenti, si prevede un filtraggio preventivo e automatico dei contenuti per impedire le eventuali violazioni dei diritti d’autore.”
“Significa invertire l’onere della prova. In questo scenario non è più il titolare del copyright a dover dimostrare il plagio ma chi pubblica i contenuti a dover verificare preventivamente ogni singolo contributo confrontandolo con tutto ciò che è presente in Rete”.
La protesta di Wikipedia riguarda la possibilità che il filtro richiesto dalla legge UE sul copyright possa trasformarsi in censura. E compie una azione di forza
In realtà l’Unione Europea, in una nota, ha voluto tranquillizzare Wikipedia Italia e ha precisato che piattaforme come questa in realtà non correrebbero il rischio di dover filtrare tutti i contenuti. Nella bozza ufficiale della legge, esiste infatti il cosiddetto “emendamento Wikipedia” estensibile a tutte le piattaforme simili, che solleva dal filtraggio automatico l’invio dei contenuti, permettendo una serena prosecuzione del proprio lavoro, specie nel settore dell’informazione enciclopedica.
Una risposta che soddisfa parzialmente Wikipedia, che in realtà sa di potersela cavare. Il problema sembra essere infatti di principio, e non di specie: “L’attuale direttiva non garantisce la sacrosanta tutela di idee e contenuti nuovi, si limita a congelare la rendita di quelli già esistenti” ragiona Codogno, che conclude: “Sebbene Wikipedia probabilmente troverebbe le forze per sopravvivere alla tempesta, cosa ne sarà dei siti più piccoli? Chiuderebbero, e con essi anche il principio del sapere libero”.
Chi ha trovato come evitare il blocco di Wikipedia e chi non ci sta
La reazione degli utenti italiani è stata piuttosto varia. Innanzitutto, la ben nota arguzia italiana, ha già trovato il modo di superare il blocco di Wikipedia. In realtà attraverso il browser Google Chrome, sarebbe sufficiente disattivare i Javascript per poter leggere nuovamente il contenuto. In particolare sarebbe sufficiente
Aprire Wikipedia su Chrome
Cliccare sulla voce “Sicuro“, sulla sinistra della barra degli indirizzi
Cliccare su “Impostazioni“
Cercare JavaScript, e dal menù sulla destra selezionare Blocca
Chiudere la pagina delle Impostazioni e avviare Wikipedia
I commenti invece si dividono: alcuni sono sostanzialmente d’accordo con l’iniziativa. Per la tutela della libertà della rete era necessaria una operazione di forza, e le migliaia di chiamate che gli attivisti ma anche i semplici utenti faranno, peseranno considerevolmente sull’iter della legge.
Ma una fetta non certamente piccola di abituali lettori di Wikipedia non ha digerito per niente l’iniziativa. Il problema sta nelle “vittime” di questa azione. D’accordo che è necessario sensibilizzare l’opinione pubblica e invitarla ad agire, ma in realtà il totale blocco delle informazioni priva le persone più deboli, ovvero i singoli internauti, di una risorsa importante.
E’ la vecchia e pericolosa burocrazia europea a creare il problema, ma ad andarci di mezzo e a subirne i danni sono i lettori. Inoltre, Wikipedia non ha contenuto proprio: ogni singola pagina è il frutto di gratuiti e innumerevoli contributi che vengono dati dalla comunità solo ed esclusivamente a fronte di un ideale di libera conoscenza. Ma chiudendo il sito, Wikipedia ha in un certo senso affermato, e dimostrato, di essere il “proprietario” di quei contenuti.
Insomma una azione considerata da alcuni “arrogante” che ha di fatto colpito chi non c’entra nulla, nel nome di “questo è quello che potrebbe accadere se passasse la legge”. I più critici e scontenti con l’iniziativa Wikipedia arrivano a rinnegare le donazioni fatte nel corso degli anni, dimostrando di non aver gradito per nulla l’iniziativa (senza discussione) del portale.
La Riforma UE sul copyright. Cosa dicono gli articoli contestati
Il primo considera il fatto che gli aggregatori di notizie prelevano titolo, foto e un piccolo riassunto dei contenuti scritti dai principali quotidiani online, dai più grandi ai più piccoli. Tuttavia la riproduzione di questo contenuto porta spesso gli utenti a comprendere la notizia senza bisogno di cliccare sul link e raggiungere chi ha realmente creato la risorsa.
Per ovviare a questo problema è stata proposta una norma chiamata “link tax“, secondo cui una sorta di tassa sul link dovrebbe essere pagata dagli aggregatori e incassata dagli editori per pagare il loro lavoro. Se anche potrebbe sembrare corretta dal punto di vista teorico, la realtà è che gli aggregatori avrebbero un potere contrattuale infinitamente superiore rispetto ai singoli quotidiani online.
I quali si troverebbero costretti a permettere ufficialmente il prelievo del contenuto, rendendo inutile la legge. In alternativa sarebbero costretti ad andarsene da piattaforme come Google News perdendo la stragrande maggioranza delle loro visite.
L’articolo numero 13, il secondo contestato, impone a tutte le piattaforme che raccolgono contenuti spontaneamente inviati dagli utenti, di eseguire dei controlli preliminari e automatici per verificare se ogni risorsa vìola il diritto d’autore di qualcuno. Le principali associazioni per la libertà dell’informazione temono che questo possa diventare uno strumento di controllo e di censura nei confronti dei contenuti di tutta internet, a parte la difficoltà tecnica di implementare soluzioni del genere.
Anche le principali personalità del web hanno scritto una lettera ufficiale, dichiarandosi preoccupati per gli sviluppi di questa legge.
Cos’è il Deep Web e il Dark Web? Cosa si trova in questo mondo sotterraneo? Quello che vediamo tutti i giorni sulla rete è solamente la superficie. Ma nelle profondità di Internet, nascoste ai più, c’è un mondo di documenti, report, dati sensibili. Un pianeta di conversazioni riservate su temi delicati. E ancora più in basso un universo illegale, di droga ed armi, di pedofilia e di spettacoli raccapriccianti e di killer su commissione.
Gli esperti di Alground vi portano in un viaggio nel Deep Web e ancora più giù, nel Dark Web, alla scoperta di tutto quanto non immaginate esista su internet.
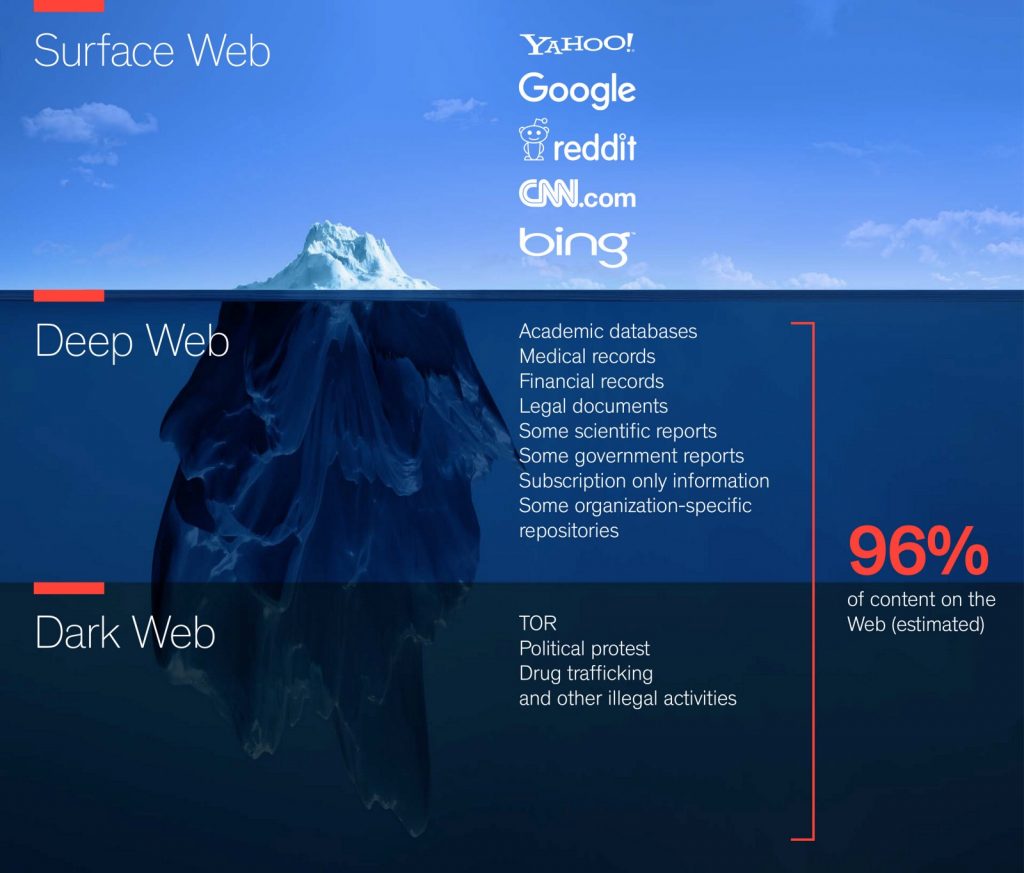
Le tre parti del web. La zona visibile ai più, il Deep Web con contenuti riservati e accessibili dagli esperti e il Dark Web, regno di attività illegali e pericolose
Per far capire con una immagine i vari strati di internet, si utilizza universalmente l’immagine di un iceberg. La punta è il Surface Web, la parte più visibile. Sotto l’acqua il deep web, e nelle profondità del mare il Dark Web. Oggi scopriamo in un viaggio sempre più profondo, cosa può riservare la rete.
Prima del Deep e Dark Web: il Surface, la parte “chiara” di internet
Il primo livello della nostra avventura è rappresentata dal “Surface Web“, cioè di quello che sta alla superficie.
Uno dei pilastri di internet sono i motori di ricerca: questi, attraverso dei software automatici chiamati crawler, scandagliano le pagine di internet. I programmi verificano i contenuti dei siti, seguono i link, leggono le directory che raccolgono i principali portali esistenti. Alla fine, i dati raccolti sono conservati in enormi database per essere restituiti a qualsiasi utente quando fa una ricerca nella mascherina, ad esempio di Google.
Questo è il “Surface web“, ovvero la parte visibile, normalmente accessibile e catalogabile senza troppi sforzi di internet.
Di questo mondo fanno parte i normali siti di informazione, gli e-commerce più famosi, i social network che usiamo comunemente (almeno una loro parte). Insomma è il web che conosciamo.
Ebbene, provate a pensare a tutta la sterminata e immensa quantità di dati che possiamo consultare sulla rete in questa modalità “normale”. Tutto questo è solamente il 10% dell’intero contenuto della rete. Perchè il 90% è altrove, nei livelli più profondi, dove non tutti possono scendere.
Immaginiamo di nuovo i motori di ricerca e i loro crawler: stavolta i software che devono raccogliere i contenuti si trovano di fronte a dei blocchi. I contenuti che emergono dalle pagine web dopo che premiamo un pulsante di invio, il cosiddetto contenuto dinamico, ma anche testi inseriti in immagini e video, fino ai contenuti premium, che bisogna pagare per leggere, o pagine che non sono linkate da nessuna parte.
Tutti questi limiti, impediscono ai crawler di accedere ai contenuti e di schedarli e organizzarli per renderli disponibili al grande pubblico. Si tratta di dati che non sono più immediatamente accessibili e per poter essere raggiunti gli utenti devono avere delle capacità più ampie della norma. Devono conoscere l’esatto indirizzo URL della risorsa che cercano o essere avviati da qualcuno verso un contenuto.
Questo è il deep web, la parte più profonda di internet.
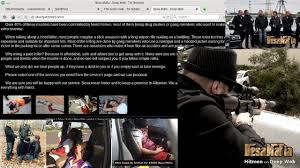
Per chi volesse fare una piccola prova, esiste Hidden Wiki. E’ una specie di “porta” per principianti al deep web, e contiene i link diretti di risorse che altrimenti non sarebbero disponibili.
Cosa troviamo in questo mondo? Siamo ancora nella parte (abbastanza) “accettabile” di internet. E’ il caso di ricerche scientifiche, normalmente sotto forma di documenti .rtf o .pdf che fanno luce su un determinato argomento e che sono un po’ pesanti da leggere. Un’altro esempio sono i dati medici: cartelle, statistiche e dati medicali che sono stati rilasciati, più o meno inavvertitamente, dagli ospedali e dalle cliniche.
Per accedere al Deep Web è necessario usare software appositi e conoscere direttamente gli indirizzi delle risorse che si cercano. Un mondo diverso e riservato agli utenti più esperti
Ci sono poi i social network o i forum privati. Non luoghi di ritrovo virtuali e abbastanza “nascosti” per parlare di diversi argomenti. Dalla politica all’ingegneria, o magari “piazze virtuali” per poter condividere del contenuto sessuale ancora perfettamente legale ma abbastanza osè. Ci sono poi i documenti finanziari: report su banche, mercati e andamenti di borsa stilate dalle varie aziende specializzate, che sono comprensibili solo dagli addetti ai lavori.
Un grande portale del Deep Web, famoso in tutto il mondo, è certamente Wikileaks. Fondato dall’attivista Julian Assange, contiene documenti, rivelazioni, report e statistiche non ufficiali sui vari governi. A questo livello siamo ancora “abbastanza” nel legale, ma certamente i documenti e le risorse che troviamo iniziano ad essere in qualche modo riservate, e dunque vanno raggiunte e consultate con una certa dose di prudenza.
Per la precisione, Wikileaks è raggiungibile anche da un normale utente, ma è solo attraverso alcuni canali riservati che si possono ottenere le informazioni più utili.
Il Deep Web è in realtà un mondo utilissimo. E’ una zona amplissima e riservata, nascosta dalla luce del sole, che è terreno fertile per lo scambio di informazioni sensibili. Viene usato innanzitutto dai giornalisti, specie quelli investigativi che hanno bisogno di confrontarsi su temi caldi senza dare troppo nell’occhio. In questo mondo troviamo anche i dissidenti politici, che a dispetto dei Governi, si passano informazioni, rivelazioni o trucchi per sfuggire ai firewall e ai controlli governativi.
Julian Assange, fondatore di Wikileaks. Il portale riunisce documenti riservati e rivelazioni. Sebbene raggiungibile anche dai normali utenti, è attraverso link del Deep Web che si possono individuare le informazioni più nascoste
Anche gli eserciti dei vari paesi, accedono al Deep Web, per raccogliere informazioni, utilissime per qualsiasi organizzazione di difesa.
Il Dark Web. Cos’è e cosa si trova nella zona oscura di internet
Il Dark Web è la parte totalmente inaccessibile ai normali utenti, utilizzata sostanzialmente per una vasta serie di traffici illegali. E’ dove si trova il peggio della rete.
Qui vige una regola fondamentale: l’anonimato. Per accedere al Deep Web, infatti, bisogna essere completamente invisibili. Per farlo lo strumento di riferimento è TOR. Ideato dai servizi segreti americani nei decenni scorsi e diffuso alla comunità civile nel 2004, TOR è un sistema che pone tra il proprio computer e quello dei destinatari una serie di terminali intermedi. Come fossero gli strati di una cipolla.
TOR è il sistema di anonimizzazione principe per utilizzare il Dark Web. Assieme alla moneta virtuale e senza identità dei Bitcoin, è un caposaldo del lato “oscuro” della rete
In questo modo, il traffico e i dati scambiati attraverso questi “nodi” intermedi, diventa cifrato e anonimo, e la propria identità viene efficacemente camuffata. Si tratta di uno strumento estremamente potente e affidabile: durante il famoso scandalo del Datagate, quando vennero rivelati i movimenti dei servizi segreti americani dell’NSA, si venne a sapere che nemmeno gli 007 USA, a parte pochi casi isolati, erano riusciti a districare l’anonimato di TOR.
In alternativa a TOR, esistono altri strumenti minori, come I2Pe Freenet. Oppure Anonabox, un piccolo router per la connessione ad internet con tutti gli strumenti preinstallati per navigare in completa segretezza.
Nel Dark Web, oltre alla segretezza di TOR, esiste un altro pilastro: la valuta digitale, e anch’essa anonima, dei Bitcoin.
Si tratta di una vera e propria moneta digitale: si accede ad una piattaforma di scambio, e con dei soldi reali si comprano i primi bitcoin. Dopodichè, questi “dollari digitali” possono essere usati per acquistare beni e servizi online, con una caratteristiche fondamentale. La transazione è tracciata e visibile a tutti per sempre, ma l’identità di chi paga e di chi riceve è totalmente coperta.
Va da sè, che i Bitcoin sono diventati la valuta corrente del mondo sotterraneo e illegale del Dark Web.
Il dark web: immense piattaforme di droga e armi
Cosa si trova nel Dark Web? innanzitutto, droga e ogni tipo di sostanza. Esistono dei veri e propri e-commerce nascosti, chiamati “Black Market”, dove si vendono in maniera sistematica, generi illegali. Dalla Cannabis alla marijuana, per arrivare alle droghe pesanti come ecstasy, eroina e cocaina. Ma anche medicinali per stimolare i rapporti sessuali, allucinogeni e farmaci antidepressivi, ansiolitici e psicofarmaci, che normalmente avrebbero bisogno di ricetta medica.
In secondo luogo: armi. Armi più leggere come scacciacani e pistole corte, fino ad armi da fuoco in dotazione alle forze dell’ordine o fucili da caccia, per arrivare, anche se bisogna cercare bene e pagare molto, a mitragliatori, piccole bombe e bazooka. Gadget presenti e molto richiesti, anche bombe molotov, bottiglie incendiarie e una vasta gamma di esplosivi, dai più semplici ai più complessi.
Un grande esempio di questo fenomeno fu Silk Road. E’ stato l’e-commerce illegale, che lavorava interamente nel Dark Web, più importante e fornito di sempre, che tramite pagamenti in Bitcoin ha incassato in pochi anni, dal 2011 quando nacque, decine di milioni di euro.
Tra le forze dell’ordine e i suoi fondatori, si scatenò una guerra feroce: fino a quando gli investigatori trovarono su Reddit, un social network usato per condividere documenti, alcuni utenti che parlavano tra di loro, di come il proprietario di Silk Road si fosse lasciato sfuggire dei dati identificativi. Avevano ragione: un collegamento errato di TOR, aveva diffuso le generalità degli amministratori del sito, e la polizia USA riuscì a smantellare interamente il mondo di Silk Road.
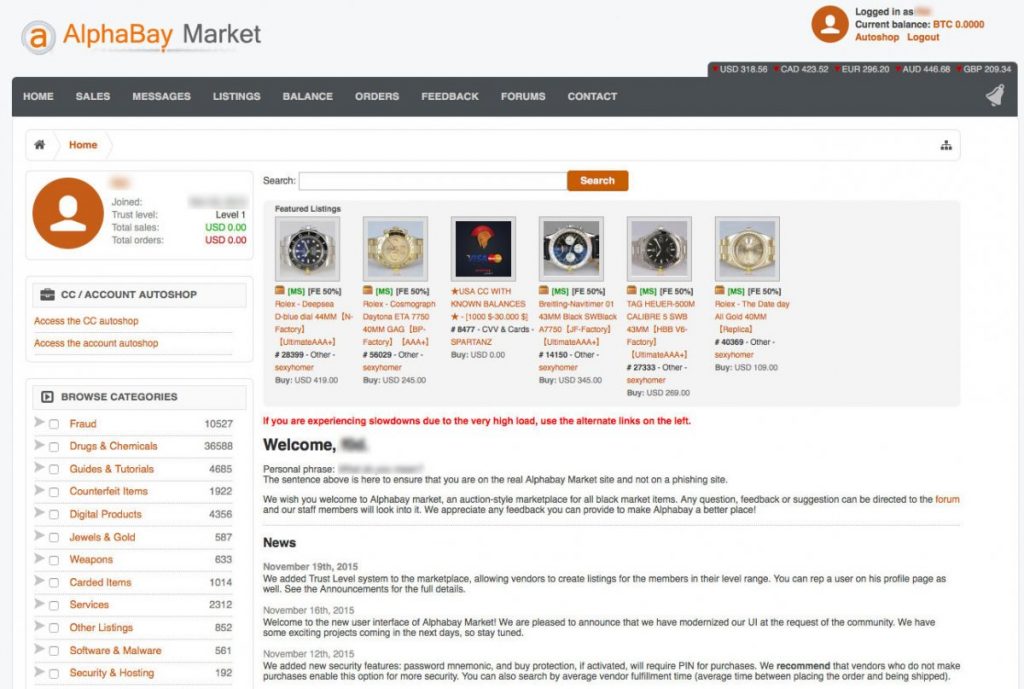
Ancora più grosso e potente fu il suo successore: Alphabay. Il suo fondatore, Alexandre Cazes, riuscì a fondare uno sterminato impero di e-commerce illegale. Milioni e milioni di prodotti vennero venduti in pochi mesi e Cazes diventò in pochissimo tempo veramente straricco. La polizia lo inseguì per mesi e riuscì a trovare solo pochi dati su di lui: la sua mail personale [email protected] e il suo nome virtuale, Alpha02.
Come un normale e-commerce, AlphaBay fu un pilastro del Dark Web, dove era possibile comprare droga, armi, prodotti contraffatti, software e virus
Fu in realtà la sua ostentazione a tradirlo. La quantità immensa di soldi che era riuscito a creare non poteva essere esibita pubblicamente, ma in un forum cui partecipava, un utente lo sfidò a dimostrare che veramente era ricco. Non riuscì a trattenersi e pubblicò la sua foto a fianco di una Porsche nuova fiammante: fu così che gli investigatori incrociarono i dati e capirono che si trovava nelle Filippine. E lo arrestarono.
La vita di Cazes finì poco tempo dopo, in carcere, per un (tutto lascia pensare) suicidio.
I black market, comunque, abbondano in tutto il Dark Web, e la compravendita di materiale illegale è un business multimilionario.
Il dark web: il regno dei pedofili
Un’altro raccapricciante pilastro del Dark Web è rappresentato dalla pornografia minorile. In un mondo anonimo, l’essere umano si abbandona agli istinti più bassi, e questa parte oscura del web è il paradiso di ogni tipo di pervertito o di pedofilo. Un nome su tutti: PlayPen. Un portale di pedopornografia che ha raccolto miliardi di visualizzazioni, e che ha diffuso una quantità di materiale relativo a bambini stuprati e oscenamente truccati che ha del vomitevole.
Le forze dell’ordine cercarono per anni di smantellare la tratta delle immagini di bambini, e ci riuscirono soltanto grazie ad un errore degli organizzatori. In sostanza, l’indirizzo IP del server che gestiva PlayPen uscì dalle maglie di TOR e trapelò pubblicamente.
La polizia dunque, fu in grado di localizzare i computer e i proprietari della piattaforma. Ma non fu solo questo: gli investigatori presero una decisione coraggiosa ma anche molto controversa. Mantennero il sito attivo, e aggiunsero sulle pagine di PlayPen un virus che colpiva il browser Firefox (necessario per l’uso di TOR), con lo scopo di infettare e controllare anche coloro che navigavano nel portale e che scambiavano materiale.
Il Dark Web è anche il regno della pedofilia. Immensi portali come Playpen o come la rete di siti gestita da un adolescente di Melbourne, hanno raccolto il peggio degli istinti umani
Furono migliaia le persone identificate e denunciate, anche se questo significò continuare a smerciare consapevolmente per diversi mesi materiale pedopornografico.
Ma legato al mondo della pedofilia, emerse anche un altro nome. Matthew Graham, nome in codice “Lux”. La sua storia sembra quella di un film ed effettivamente potrebbe esserlo: è infatti il racconto di un adolescente taciturno e complessato. Ignorato dai compagni che vive interi pomeriggi nella sua camera.
Questo ragazzo, emarginato dalla società e rinchiuso nel suo mondo, ha scandagliato per mesi il Dark Web, ed ha fondato il più grande impero della pedofilia online che esista. Non solo la quantità di materiale a disposizione dei pedofili di tutto il mondo, ma soprattutto una cosa ha colpito gli investigatori: la disarmante crudezza e cattiveria del materiale condiviso, che non si fermava solamente al lato sessuale, ma si perdeva in pratiche di tortura che hanno letteralmente disgustato i poliziotti.
Graham, sempre per un errore di percorso che ha permesso di individuarlo, è stato trovato e arrestato, mostrandosi al mondo per quello che è. Un essere schifoso, perso nelle sue perversioni, che ha trovato nel Dark Web terreno fertile per la fuoriuscita del peggio che l’essere umano possa concepire.
Il dark web: audio morbosi e spettacoli di torture
Il Dark Web è luogo, per rimanere in tema, di orrore e di morbosità. Ci sono due grandi “passatempi” in questo senso. Il primo è la condivisione di immagini raccapriccianti: da operazioni chirurgiche mal riuscite, ad incidenti a deformazioni di ogni tipo. Questi contenuti vengono spesso utilizzati anche per combinare scherzi di pessimo gusto ad altre persone.
Una alternativa più recente sono le registrazioni audio: un grande classico sono gli audio delle scatole nere degli aerei poco prima della loro caduta, con le urla dei passeggeri o le ultime parole dei comandanti. Altri audio comuni sono i gemiti di persone malate, di gente “posseduta” o di pazienti negli ospedali psichiatrici.
Un altro classico è quello della cosidetta “Red Room”. Si tratta di veri e propri show, dove un aguzzino si diverte a torturare una persona: pagando è possibile assistere allo spettacolo e addirittura suggerire delle mutilazioni o delle sofferenze da infliggere alla vittima. In alcuni casi si tratta di Creepy Pasta, racconti horror verosimili, ma in altri casi esistono veramente incontri sul web dove la tortura è il divertimento della comunità.
Il dark web: un mondo di hacking e servizi illegali
Altro grande tema del Deep Web sono i servizi illegali a bassissimo costo. Si parte dalla creazione e vendita di documenti falsi: carte d’identità, patenti di guida e soprattutto passaporti, specie tedeschi, americani e italiani, che a livello mondiale sono quelli che danno meno nell’occhio. In una vera e propria “fattoria” delle identità, si danno precise indicazioni ai criminali informatici, che inviano direttamente a casa o in punti di raccolta selezionati i documenti: il costo varia dai 200 ai 1000 dollari.
Passaporti falsi, virus bancari, hacking di email e di profili social. Si possono trovare sterminate offerte illegali nel Dark Web. Fino a servizi che promettono di uccidere persone su commissione
In vendita ci sono anche diversi servizi di hacking: si possono affittare dei pirati informatici per accedere ad account di posta online o per prendere possesso di profili social (pagando dai 50 ai 200 dollari). Si possono anche comprare dei virus da utilizzare contro le proprie vittime. Il codice di un virus trojan si vende dai 150 ai 400 dollari, mentre un malware per svuotare i conti correnti bancari (altamente personalizzabile per le proprie esigenze) è sul mercato attorno ai 900/1500 dollari.
Per chi volesse mettere fuori gioco il sito web di un concorrente, è possibile noleggiare una rete di computer compromessi (botnet) e sferrare un attacco di tipo DDoS. In questo caso si invia una quantità ingestibile di richieste ai server vittima, mettendo offline il sito del proprio “nemico”. Un servizio del genere costa circa 1500 dollari per 24 ore.
Esiste poi un servizio ai limiti della realtà. Non si sa esattamente se esista davvero o se sia solamente una grande truffa organizzata. Si chiama Besa Mafia, ed è un portale che consente agli utenti di commissionare a dei killer professionisti l’omicidio di una persona. In questo caso è necessario fornire i dettagli e le generalità della vittima, e viene fatta una stima caso per caso del tempo e dei soldi necessari per completare l’operazione.
Ad onor del vero non esistono evidenze che Besa Mafia sia un servizio reale, ma gli investigatori possono affermare una cosa per certa: il portale è frequentatissimo, e i gestori hanno raccolto una lista ingente di persone da (potenzialmente) uccidere assieme ad una quantità di denaro certamente non trascurabile. Insomma, un altro esempio lampante dei bassifondi di internet.
La testimonianza di chi ha vissuto Deep e Dark Web
Proprio in questi bassifondi si è immersa la blogger e giornalista Eileen Ormsby, che ha scritto un libro che ricorda la sua esperienza. Al magazine Vice.com, una intervista che ci dà un “assaggio” di cosa può essere davvero il Dark Web, di cui riportiamo un estratto.
Il Deep Web è davvero un’altra cosa rispetto al mondo reale? Le nostre vite sono talmente tanto online che il mondo online è il mondo reale. Non c’è più nessuna differenza. La cosa che contraddistingue il deep web è la segretezza. Il che dà voce alle persone che normalmente non l’avrebbero. È usato anche da informatori o da gente che vive in paesi in cui vigono regimi oppressivi.
Ma può anche far sì che le persone facciano cose che non avrebbero mai fatto nella loro vita reale. Lo sfigato che non ha mai picchiato qualcuno nella vita, può improvvisamente essere un boss del male.
Hai indagato su “Lux”, ovvero Matthew Graham, il giovane che gestiva i peggiori siti pedofili del Dark Web dalla sua camera da letto. Eri presente alle udienze contro di lui e lo hai visto di persona. Che tipo è? E’ un ragazzino patetico, senza amici, triste. Era socialmente inetto. Aveva un sacco di problemi e il dark web era il suo modo di essere importante. Ma era un patetico perdente. È quasi triste, a parte il fatto che era così odioso che non si riesce a provare pena per lui. Ho visto suo padre in quelle sedute di tribunale. Era un uomo distrutto, sconvolto da ciò che suo figlio faceva sotto il suo naso.
C’è un filo comune che collega le persone attive nel Dark Web? Devi avere un certo livello di conoscenza tecnica. Tendenzialmente l’utente medio è impiegato, maschio, molti vengono dai paesi occidentali, di lingua inglese, principalmente dagli Stati Uniti, dall’Europa e dal Regno Unito. Il linguaggio utilizzato nella maggior parte del dark web è l’inglese, anche se ora ci sono un sacco di forum di lingua russa.
Sei entrata anche nel portale Besa Mafia, il più grande sito web di omicidi a contratto. Come è andata? Besa Mafia era un sito molto elegante che molte persone pensavano fosse autentico. Utilizzando alcuni file trovati dal mio amico Chris Monteiro, abbiamo ottenuto l’accesso al database e alla casella di posta del sito. È stato un po ‘sconcertante quando il proprietario del sito ha iniziato a minacciarmi. Sembrava essere un po’ sconvolto.
Besa Mafia è un portale che promette di uccidere persone su commissione. In alcune pagine i dettagli del presunto servizio e delle immagini di “lavori” già svolti. La foto è stata annebbiata per motivi di sicurezza
Il database mostrava una lista di persone reali che erano disposte a pagare per far uccidere qualcuno. Che cosa hai fatto? Circa due dozzine di persone avevano pagato a Besa Mafia migliaia di dollari in Bitcoin per far uccidere delle vittime. Per lo più erano situazioni tra marito e moglie o amanti rifiutati, con un mix di uomini e donne, provenienti da tutto il mondo.
Che consiglio daresti alle persone che esplorano il deep web per la prima volta? La prima cosa è fare informarsi. Leggere tutto ciò che si può prima di entrarci. Bisogna farsi un’idea di cosa è reale e cosa non è reale e quali sono le truffe che girano. Se vai nel deep web e fai clic sul primo link che trovi, sarà un link di phishing. Non fare clic su collegamenti che non sai dove vanno.
Al di fuori dei mercati neri, e persino all’interno, a volte, quasi ogni sito che chiede pagamenti con la tua criptovaluta li prenderà e non ti darà nulla in cambio. Gli utenti devono essere costantemente all’erta per non accedere a uno dei numerosi siti di phishing che ripuliscono i loro account Bitcoin.
I sostenitori del Dark Web dicono che è uno spazio vitale per la libertà e la privacy online. E’ solo una scusa? Non credo affatto. Ogni volta che fai un clic stai dicendo a qualcuno qualcosa in più su di te, e tutti se lo vendono l’un l’altro. Penso che ci siamo arresi a questa dinamica e che lo abbiamo fatto senza nemmeno rendercene conto. I bambini sono cresciuti senza conoscere alcuna privacy. Mettono tutto online, è normale per loro. Non sappiamo quanti dati stiano accumulando i big di internet o in che modo queste informazioni verranno utilizzate in futuro.
Come vedi il futuro del dark web? Penso che ci siamo trasferiti in un mondo post-privacy quasi senza accorgercene. Molte persone si accontenterebbero di rinunciare alla loro privacy per il gusto di vivere facilmente. Ma penso che vedremo un movimento molto più forte che cerca di riprendere il controllo delle informazioni perché alcune persone semplicemente non vogliono rinunciare a tutti i loro dati per fare contenti i marketer. Gli strumenti per la privacy, come quelli forniti dal dark web, saranno più integrati nella tecnologia, in modo che ognuno di noi possa decidere a quanto è disposto a rinunciare.
Quando si dice che i criminali non guardano in faccia a nessuno è vero. E gli hacker, nei prossimi anni, potrebbero prendere di mira pacemaker, strumenti per i diabetici, protesi e altri apparecchi medici. Per ora si tratta solo di dimostrazioni scientifiche ed esperimenti, ma le aziende e i pazienti devono capire che anche la sanità è suscettibile di attacchi informatici, e deve includere la sicurezza degli strumenti fra le priorità.
La medicina utilizza sempre più componenti tecnologici e connessi alla rete. E questo non solo per le funzionalità, ma che per il monitoraggio: un pacemaker in grado di inviare statistiche sui battiti del cuore o una pompa insulinica programmata dal personale medico, hanno dei vantaggi enormi per gestire le cure.
Ciononostante, se da un lato gli strumenti sono più potenti perchè connessi, sono anche più passibili di attacchi.
Quando gli hacker attaccano i pacemaker
E’ dal 2008 che sono emersi i primi studi in materia, ma il caso più eclatante è certamente quello del 2016. L’azienda di sicurezza MedSec, che da anni monitorava l’affidabilità dei dispositivi medici, si accorse che i prodotti della St. Jude Medical non era sicuri, in quanto mancavano sia di autenticazione (password) si di sistemi di criptazione per proteggere le proprie connessioni. L’azienda, che aveva anche un proprio tornaconto personale, avvisò la compagnia di valutazione finanziaria Muddy Waters, che diramò la notizia causando una considerevole perdita in borsa alla St. Jude.
Ma aldilà del dispetto finanziario, il dato tecnico rimane.
Un pirata informatico, con una strumentazione abbastanza elementare come un PC, un radio connessa ad internet e dei software reperibili gratuitamente sul web, può inviare un consistente numero di segnali contraddittori a pacemaker, defibrillatori e risincronizzatori del cuore impiantati direttamente nei pazienti.
Il risultato possono essere dei gravi malfunzionamenti dell’apparecchio, che possono tradursi in fibrillazioni ventricolari o in gravi aritmie.
Una seconda tecnica di attacco riguarda invece la batteria. Tramite una serie di impulsi, si indica al dispositivo di modificare la propria gestione della batteria. In alcuni test la pila è stata ridotta al 3% di carica, vicinissima allo spegnimento, per 24 ore. Per eseguire l’attacco l’hacker deve trovarsi comunque in prossimità della vittima entro un raggio di 15 metri.
Momento iconico in questo settore, la dimostrazione pubblica dell’esperto di sicurezza presso McAfee, Barnaby Jack, che inviò ad un pacemaker funzionante una scossa di 830 volt, che avrebbe ucciso una persona all’istante.
Non solo il cuore. A rischio hacking anche gli apparecchi per l’insulina
Un’altra categoria di prodotti a rischio è certamente quella destinata ai diabetici.
I pazienti che soffrono di malattie metaboliche usano spesso delle pompe insuliniche, ovvero dei piccoli oggetti da portare con sè come uno smartphone, che iniettano sottopelle delle quantità previste di insulina ad orari determinati.
Anche in questo caso un pirata informatico può utilizzare delle frequenze radio per inviare comandi errati al dispositivo: basta modificare una virgola, ovvero indicare ad una pompa insulinica di iniettare non 0,2 ml ma 2,0 ml di sostanza ad un determinato orario per uccidere un diabetico in poche ore. Oppure, si può indicare alla pompa di scaricare nel sangue della vittima tutto il contenuto di insulina in una volta sola, come ha fatto sempre Jack nella sua dimostrazione pubblica.
Anche in questo caso, l’hacker deve trovarsi in prossimità della vittima, ad un massimo di una trentina di metri.
Una aggravante, sta nel fatto che attacchi come questi sono molto difficilmente rilevabili durante una ipotetica autopsia. Non solo non rimangono tracce nel dispositivo, ma pochi medici arriverebbero a pensare ad una disfunzione dell’apparecchio, e pochissimi avrebbero le competenze forensi necessarie per verificare se vi sia stata una intromissione a distanza.
Pacemaker, pompe di insulina ma anche stimolatori gastrici e impianti cocleari. Diversi apparecchi sono vulnerabili ad attacchi hacker. Ma per ora il rischio è ancora teorico
Insomma, dell’attacco non rimane alcuna traccia dopo la morte.
Se queste dimostrazioni rimangono per ora nel campo della sola teoria, le statistiche aggiungono degli elementi abbastanza preoccupanti.
I numeri del fenomeno e i primi episodi reali
La società di sicurezza Trend Micro, ha utilizzato un motore di ricerca apposito, Shodan, per cercare da remoto dispositivi medici rilevabili e vulnerabili ad attacchi di questo tipo e ne ha individuati 100mila in poche ore. Insomma, chiunque potrebbe cercare e trovare un grande quantitativo di apparecchi scoperti.
Un caso concreto, anche se fortunatamente circoscritto, avvenne nel maggio del 2017. A quei tempi il Governo della Corea del Nord, utilizzò una vulnerabilità di Windows scoperta qualche tempo prima dai servizi segreti americani dell’NSA e inavvertitamente pubblicata, per lanciare un attacco agli USA.
Gli hacker nord coreani trovarono migliaia di computer di ospedali e cliniche private con una vecchia versione del sistema operativo, e riuscirono a bucare i dispositivi Bayer Medrad, che si utilizzano nel campo della diagnostica per immagini. In quella occasione, per fortuna, il tutto si tradusse con un aggiornamento dei sistemi e con qualche radiografia rimandata di alcune ore, ma tecnicamente è la prova che un attacco a sistemi sanitari è concretamente possibile.
I dati preoccupanti e quelli che ci tranquillizzano
Il pericolo è potenzialmente molto elevato, ma per riequilibrare il discorso prendiamo considerazione alcuni elementi. Alcuni preoccupanti e altri incoraggianti.
Il primo elemento preoccupante è sicuramente il fatto che per eseguire questo tipo di attacchi non bisogna avere una preparazione tecnica elevatissima. L’utilizzo del wifi, delle onde radio e l’invio di segnali sono argomenti alla portata di qualsiasi studente medio di informatica e gestione delle reti, per cui chiunque potrebbe sviluppare in poco tempo le capacità necessarie a lanciare degli attacchi.
Il secondo punto “non molto bello” è che i costi, una volta piuttosto elevati, si sono abbassati drasticamente: alcuni apparecchi necessari per compromettere i pacemaker sono ormai acquistabili su eBay a poco prezzo. Un attacco su una pompa insulinica, è stato eseguito da un hacker con una scheda Arduino di poco meno di 20 euro.
Una parte importante del problema sta poi nel fatto che gli ospedali e il personale medico sono largamente impreparati ad uno scenario simile e molto spesso non immaginano neanche che si possa hackerare un pacemaker. Nel caso in cui dovessero essere “aggiornati” i dispositivi, proprio per proteggerli da attacchi informatici, sarebbe poi necessario per i pazienti recarsi in ospedale.
Non sono necessari interventi chirurgici invasivi, questo no, ma l’operazione deve essere comunque eseguita in day hospital da personale medico.
Barnaby Jack di McAfee: ha dimostrato pubblicamente come si può spingere un pacemaker a scaricare 800 volt nel cuore o svuotare una pompa insulinica in pochi minuti in un diabetico. Tutto a distanza di circa 30 metri
Un fattore che può mitigare il pericolo, è la distanza. L’aggressore deve comunque trovarsi ragionevolmente vicino o perlomeno nella stessa area della vittima, e questo esclude attacchi da remoto.
Più rassicurante, il lato puramente economico.
A parte il fatto che un hacker che dovesse uccidere persone tramite questo tipo di attacchi si ritroverebbe qualsiasi forza dell’ordine sulle sue tracce, dove sarebbe il guadagno? In altre parole: il pirata informatico potrebbe anche chiedere denaro per non sferrare l’attacco ad un paziente-vittima, ma come potrebbe riscuotere? Posto che deve essere ragionevolmente vicino al suo target, il passaggio di denaro sarebbe fisico e tracciabile.
Insomma, non ci sono i presupposti perchè questo scenario, almeno nel breve periodo, si trasformi in una fonte di guadagno illecito.
Infine, alcuni produttori stanno mettendo in campo delle prime soluzioni, come degli “scudi di frequenza” per bloccare onde radio irregolari, anche se si tratta di tecniche piuttosto rudimentali.
Non possiamo gridare all’allarme. Come detto, anche se tecnicamente esiste la possibilità di hackerare dispositivi medici, vi sono degli elementi come la prossimità al target e l’impossibilità di riscuotere denaro che mantengono questo argomento ancora nel campo della teoria tecnico-informatica.
Ma è un segno dei tempi: a mano a mano che i dispositivi diventeranno sempre più intelligenti, i pericoli seguiranno di pari passo e la posta in gioco, in molto più di un caso, potrà essere ben più grave di un semplice pc o smartphone inutilizzabile.
La riforma dell’Unione Europea sul copyright sta spaventando tutta internet: blocco delle news, fallimento dei piccoli editori, filtri ai contenuti e censura. Si parla di “morte dei meme” e di “addio YouTube”. Gli esperti di Alground hanno analizzato in maniera approfondita la legge approvata recentemente dal Parlamento Europeo: vi spiegheremo cosa dice e perchè potrebbe essere una catastrofe. Ma anche come venirne fuori.
Vi proponiamo prima alcune domande e risposte per comprendere rapidamente i punti del discorso e successivamente potete leggere l’intero dossier per una trattazione completa.
COSA DICE LA RIFORMA UE DEL COPYRIGHT?
Ha tanti articoli e molte norme, ma i punti focali sono due: la difesa degli editori dagli aggregatori di notizie e dei controlli per bloccare preventivamente le violazioni del diritto d'autore.
COSA DICE L'ART. 11 E DOVE E' IL PROBLEMA?
Dice che coloro che inseriscono un link ad un articolo assieme ad un riassuntino o ad un estratto del contenuto, devono pagare una tassa all'editore che ha scritto quel contenuto (tassa sul link). Stessa cosa per le piattaforme che propongono titolo, foto e un estratto del testo di una news (gli aggregatori tipo Google News).
Ma all'atto pratico mentre gli aggregatori sono potenti, i singoli siti no, perchè le loro letture dipendono spesso dalle queste piattaforme. Non hanno pari potere contrattuale.
Quindi se i piccoli giornali scelgono di andarsene dagli aggregatori, perdono tutte le visite, e se gli danno il permesso di prendere i loro contenuti, è tutto come prima e la legge diventa inutile. Alla fine gli unici a poter contrattare alla pari sono i grandi gruppi editoriali di ogni paese.
COSA DICE L'ART. 13 E PERCHE' NON VA?
L'art. 13 dice che quando un utente carica un contenuto su una piattaforma (tipo Youtube), il sito deve verificare tramite dei filtri che non sia materiale protetto dai diritti d'autore. Questo per evitare violazioni del copyright.
Il problema sta nel fatto che tutti i contenuti sono filtrati. Come se i postini aprissero le lettere per controllare che non ci siano illeciti. Inoltre un meccanismo del genere può rapidamente portare al blocco di attività sacrosante come la satira. Addirittura potrebbe trasformarsi in censura.
E' GIA' AVVENUTO QUALCOSA DI CONCRETO?
La Cina blocca Twitter, la Russia i siti LGBT e l'Ecuador usò la scusa del copyright per bloccare decine di siti che criticavano il Governo, il rischio è reale.
L'ATTUALE LEGGE ITALIANA COSA PREVEDE?
Per il discorso delle news, non c'è ancora una normativa specifica. Per il copyright tutti i contenuti possono essere caricati online. Poi se il proprietario dell'opera segnala una violazione del contenuto, la piattaforma la deve rimuovere. L'ente italiano, che può intervenire anche oscurando siti o pagine web è l'AGCOM.
A CHE PUNTO E' LA LEGGE?
E' stata approvata dal Parlamento Europeo. Ora deve passare al consiglio, dove ogni stato membro dovrà dire la sua, e poi ci sarà la votazione finale.
SE VOGLIO MANIFESTARE CONTRO LA LEGGE CHE POSSO FARE?
Puoi seguire gli aggiornamenti dell'europarlamentare tedesco Julia Reda, che guida l'opposizione a questa riforma. E sul sito Change.org puoi firmare la petizione per chiedere di bloccare il percorso della legge.
Ora che abbiamo chiarito i punti principali, partiamo inquadrando il pensiero alla base di tutto: l’Europa vuole costruire un mercato unico digitale, che permetta attraverso internet di scambiare qualsiasi cosa, dai prodotti alle informazioni su tutto il continente.
E’ con questo ideale che sono state elaborate negli anni scorsi diverse leggi. Ad esempio quella sul roaming: una volta se eri di un operatore telefonico nostrano e andavi in un altro paese, dovevi pagare una tassa per usare l’infrastruttura della nazione che ti ospitava, mentre ora non è più così. Un altro esempio più recente è la normativa GDPR, che vuole responsabilizzare le aziende nel trattamento dei dati degli utenti.
La riforma della legge sul copyright ha quindi, in linea teorica, un intento positivo, cioè quello di aiutare la comunità europea a far valere i suoi diritti.
La legge è molto lunga e complessa, ma gli articoli fondamentali sono due. L’articolo 11, che riguarda sostanzialmente la gestione delle news e delle informazioni, e l’articolo 13, che tocca la diffusione dei contenuti e il diritto d’autore.
Riforma UE sul copyright. L’art. 11 e la difesa degli editori dagli aggregatori
Per capire l’articolo 11 dobbiamo fare un piccolo passo indietro nel tempo. Negli ultimi 10 anni, i siti di informazione più o meno grandi potevano iscriversi agli aggregatori di notizie, Google News in primis, ma anche Yahoo! News , Libero(in Italia), Pulseo Flipboard.
Gli aggregatori citavano le notizie dei vari giornali e diventavano grossi e famosi, e in cambio veicolavano milioni di click ai giornali iscritti, che poi ci guadagnavano su.
Cosa è cambiato ad un certo punto? Che le piattaforme di aggregazione, hanno iniziato ad includere sempre più informazioni fino ad integrare il titolo della news, una foto e lo “snippet”, cioè un piccolo riassuntino del contenuto. E in questo modo i lettori, ad esempio di Google News, riuscivano a capire la notizia senza andare a leggere il giornale che l’aveva scritta.
E questo ha rotto l’incantesimo: alla fine ci guadagnava solo l’aggregatore che “sfruttava” gli editori.
Se lo snippet degli aggregatori riporta tutto il necessario per capire la notizia, gli utenti non hanno motivo di leggere la fonte. E’ a questo che vorrebbe porre rimedio l’art.11 della riforma UE sul copyright
Dopo tante polemiche e proposte, la legge europea, e in particolare l’articolo 11, sono stati sviluppati per raddrizzare la situazione. Secondo la norma se inserisci il link ad una notizia, con un riassuntino scritto da te o con la citazione di un pezzo dell’articolo, devi pagare una tassa all’editore. Una vera e propria “tassa sul link“.
Ma soprattutto, e questo è diretto sostanzialmente a Facebook e Google, se crei un trafiletto con Titolo, foto, snippet e link, devi ugualmente pagare l’editore.
Insomma, l’idea in sè non è cattiva, anzi. E’ una misura di giustizia nei confronti di chi lavora per produrre contenuti.
Il problema sta che fra il dire e il fare c’è di mezzo la realtà. Questa legge obbliga le piattaforme di aggregazione e i singoli siti web a rinegoziare i loro accordi. Tuttavia, mentre Google o Facebook sono immensamente potenti, il singolo quotidiano che magari deve a loro il 70% o l’80% del suo traffico, non ha lo stesso potere di contrattazione. E’ molto più debole.
E all’atto pratico se sceglie di usare la linea dura, esce dall’aggregatore e perde utenti e denaro, mentre se consente l’utilizzo pieno dei suoi snippet, ecco che la legge non è servita a nulla.
Gli unici che possono realmente parlare alla pari con le piattaforme, sono i grandi gruppi editoriali dei singoli paesi, e dunque piove sul bagnato. Si salvano sempre i soliti.
La norma imposta in Spagna, ha portato alla rottura tra Google News e gli editori ispanici. L’aggregatore non esiste più e migliaia di giornali online hanno perso traffico
Il bello, si fa per dire, è che abbiamo già delle prove concrete delle conseguenze di questa “lotta”: in Spagna non si è trovato l’accordo e Google News praticamente non esiste più, con un danno immenso nei confronti dei millemila siti che ci vivevano attaccati. In Germania, gli aggregatori citano solamente i titoli, ma alla fine sono sopravvissuti solo i grandi giornali e la situazione è più o meno la stessa.
La norma rischia, nonostante le buone intenzioni, di causare un disastro.
Riforma UE sul copyright: l’art. 13 per la protezione dei diritti d’autore
Il secondo problema è relativo all’articolo 13. Anche qui le volontà dei legislatori sarebbero le migliori, e riguardano la difesa del diritto d’autore.
Nella situazione attuale, tutti possono caricare dei contenuti online liberamente, specie sulle piattaforme che vivono sullo User Generated Content come Facebook o Youtube. Nel caso in cui il proprietario di un contenuto veda la sua opera riprodotta o condivisa senza il suo permesso, può segnalare la cosa alla piattaforma e in Italia all’AGCOM, che interviene rimuovendola.
Esiste poi il Creative Common, cioè una serie di licenze che consentono di dare una progressiva libertà al riutilizzo dei propri contenuti.
L’articolo 13, invece, dice sostanzialmente che le piattaforme devono eseguire un controllo preventivo su ogni contenuto caricato dagli utenti, al fine di verificare che non vi sia alcuna violazione del copyright e solo successivamente accettarlo e renderlo disponibile online.
Giusto nella teoria, ma di nuovo devastante nella pratica.
Innanzitutto uno dei principi fondamentali del diritto è che chiunque è innocente fino a prova contraria. Se trasferiamo questo nei contenuti, ogni contenuto è legittimo fino a prova contraria. Ma inserire a priori un filtro significa affermare l’opposto: ogni contenuto è irregolare e non pubblicabile fino al via libera di una autorità. E’ inaccettabile.
Per farvi capire un esempio non esattamente allineato ma calzante: se scrivo una lettera di insulti, il postino la recapita e sarà il destinatario a lamentarsi. Con la nuova legge, è come se il postino aprisse la busta, e leggesse per controllare che non ci siano parolacce.
L’art. 13 impone un controllo preventivo su ogni contenuto caricato online, per verificare che non vi sia violazione del diritto d’autore. Da lì alla censura, il passo è brevissimo
Il secondo problema è intellettuale: i filtri automatici non capiscono le sfumature dei significati umani, ad esempio l’ironia. Un meme che prende in giro un politico, potrebbe essere bloccato per via dell’immagine del personaggio o per la citazione di una frase, senza capire che non si vuole redistribuire contenuto protetto ma fare satira.
Il tutto potrebbe poi prendere la via della censura vera e propria. Un controllo totale su tutto quello che viene caricato online può diventare in un attimo repressivo. Penserete che sia una ipotesi lontana, ma tanto lontana non è: nel 2015, il Governo dell’Ecuador utilizzò la legge sul copyright per mettere i bastoni fra le ruote ad una dozzina di giornali online che criticavano l’operato dell’esecutivo.
Infine il problema puramente tecnico, ovvero degli errori di calcolo e dei blocchi non previsti. La tecnologia esistente più simile è il YouTube ID, che verifica l’audio di un video e lo blocca in caso di violazione. Ebbene, nel 2012, un video con un uccellino che cinguettava fu fermato perchè il suono era presente in un video musicale, e lo sbarco di un modulo della NASA su Marte, venne scambiato per qualcos’altro e rimosso. Simile sorte ad un live streaming del 2013, dove qualcuno si mise a cantare “Buon compleanno” e la diretta fu stoppata.
E dire che il sistema è stato sviluppato nel corso di 11 anni, il che fa capire quanto sia costoso. Da qui anche un altro problema: gli unici a poter avere dei filtri decenti sarebbero le grandi compagnie tecnologiche. Strada sbarrata a piccole iniziative private di condivisione contenuti.
Le proteste internazionali per bloccare la legge
Le due norme sono state accolte con enorme preoccupazione dai giganti del web. In una lettera aperta, gente come Tim Berners Lee (creatore del WWW) o Jimmy Wales (fondatore di Wikipedia), chiedono al presidente dell’Europarlamento Antonio Tajani di intervenire. La lettera recita:
[miptheme_quote author=”” style=”text-center”]
Come gruppo di architetti e pionieri di Internet e loro successori, scriviamo a Lei per una questione urgente, una minaccia imminente per il futuro della Rete.
La proposta della Commissione europea per l ‘articolo 13 della proposta di direttiva per il diritto d’autore ha le migliori intenzioni.
Condividiamo la preoccupazione che ci dovrebbe essere un’equa distribuzione delle entrate online e un corretto uso delle opere d’autore, che avvantaggiano creatori, editori e piattaforme. Ma l’articolo 13 non è il modo giusto per raggiungere questo obiettivo.
Richiedendo alle piattaforme Internet di eseguire il filtro automatico di tutti i contenuti che i loro utenti caricano, l’Articolo 13 fa un passo senza precedenti verso la trasformazione di Internet da piattaforma aperta per la condivisione e l’innovazione, in uno strumento per la sorveglianza e il controllo dei suoi utenti.
L ‘Europa ha già un ottimo modello di responsabilità, in base al quale coloro che caricano contenuti su Internet hanno la responsabilità della sua legalità, mentre le piattaforme sono responsabili di rimuovere tali contenuti una volta che la loro illegalità sia stata portata alla loro attenzione. Invertendo questo modello di responsabilità e rendendo le piattaforme direttamente responsabili di garantire la legalità dei contenuti, i modelli di business e gli investimenti delle piattaforme grandi e piccoli dovranno cambiare. [/miptheme_quote]
Jimmy Wales, fondatore di Wikipedia, e Tim Berners Lee, padre del WWW. Anche loro hanno scritto una lettera aperta al europresidente Antonio Tajani, per chiedere di bloccare la legge
[miptheme_quote author=”” style=”text-center”]
Il danno che questo può fare ad una Internet libera e aperta è difficile da prevedere, ma nelle nostre opinioni potrebbe essere sostanziale. In particolare, lungi dall’influenzare solo le grandi piattaforme Internet americane (che possono permetterselo), l’ònere dell’articolo 13 ricadrà più pesantemente sui loro concorrenti, comprese le start-up e le PMI europee. Il costo di mettere in atto le tecnologie di filtraggio automatico necessarie saranno costose e onerose.
In effetti, se l’articolo 13 fosse stato messo in atto quando i protocolli e le applicazioni di base di Internet furono sviluppate, è improbabile che Internet esisterebbe come lo conosciamo oggi. L’impatto dell’articolo 13 si ripercuoterebbe anche sugli utenti ordinari di piattaforme Internet non solo quelli che caricano musica o video, ma anche coloro che contribuiscono con le foto, testo o codice per aprire piattaforme di collaborazione come Wikipedia e GitHub.
Anche gli studiosi dubitano della legalità dell’articolo 13; per esempio, il Max Planck Institute per l’innovazione e la concorrenza ha scritto che “l’obbligo di applicare un filtro a tutti i dati di ciascuno dei suoi utenti prima del caricamento sui servizi pubblici è contrario all’articolo 15 della direttiva InfoSoc e alla Carta europea dei diritti fondamentali.
Una delle disposizioni particolarmente problematiche dell’articolo 13 come originariamente proposta dal Commissione e nei testi di compromesso del Consiglio e del Parlamento, è che nessuna di queste versioni del testo fornirebbe né chiarezza né coerenza nel tentativo di definire quali piattaforme Internet sarebbero obbligate a conformarsi e quali possono esserne esenti. L’incertezza che ne deriva guiderà le piattaforme online a lavorare fuori dall’Europa e impediranno loro di fornire servizi a livello europeo.
Sosteniamo le misure che potrebbero migliorare la capacità dei creatori di ricevere un compenso equo per l’utilizzo delle loro opere online. Ma non possiamo sostenere l’articolo 13, che imporrebbe alle piattaforme Internet l’incorporazione di un’infrastruttura automatizzata di monitoraggio e censura in profondità nelle loro reti.
Per il futuro di Internet, Vi esortiamo a votare per la cancellazione di questa proposta.[/miptheme_quote]
A combattere contro la proposta, l’europarlamentare tedesco Julia Reda, leader della fazione avversaria al nuovo regolamento, e anche semplici cittadini digitali, che sul portale Change.org hanno già raccolto 400mila firme per abolire il testo.
Il fatto che la legge abbia incassato una prima approvazione è il segnale che il Parlamento Europeo, sulla questione, ha questo orientamento. E ciò influisce in maniera determinante nel processo di ratifica definitiva delle norme. Esistono però ancora due passi: il Consiglio Europeo, dove ciascun paese membro dovrà dare la sua approvazione, e il voto finale di tutto il Parlamento.
Insomma, ci sono ancora dei passaggi, anche se la strada è abbastanza chiara.
Riforma UE sul copyright. La fine dell’Internet libera?
Ci troviamo di fronte alla fine dell’Internet libero? Secondo noi no, e sostanzialmente perchè la riforma, anche se approvata in via definitiva, dovrà poi essere applicata e adattata alla realtà di ogni specifica nazione europea. E in Italia abbiamo due armi. La prima è il Trattato di Nizza, ovvero la carta dei diritti fondamentali del cittadino Europeo, i cui articoli relativi alla libertà (6-19), potrebbero essere usati per opporsi alla legge.
E in secondo luogo, il carissimo e salvifico articolo 21 della costituzione, che sancisce il diritto alla cronaca e che potrebbe in molti casi “salvare” la libera espressione dal fuoco incrociato di regole e regolette.
Non possiamo fare altro che attendere gli sviluppi, anche se la riforma del copyright dimostra ancora una volta il modo con cui l’Europa intende l’Internet. Gli stati considerano sostanzialmente Google e Facebook come l’internet stessa, e non come due portali che ne fanno parte, e che sono i singoli consumatori od aziende a rischiare maggiormente.
Per loro le uniche vie di salvezza sono la non ancora capillarità della legge, che spesso si traduce in un nulla di fatto, e i singoli articoli delle costituzioni nazionali, che gli permettono di opporsi in situazioni al limite della logica.
La privacy e la libertà in rete, sono diritti umani fondamentali. Ma per alcuni è meno fondamentale di altri e per salvare il nostro diritto alla riservatezza potrebbe venirci in soccorso niente meno che la blockchain, la tecnologia alla base del funzionamento della moneta virtuale Bitcoin che ha però applicazioni che vanno oltre il semplice scambio di denaro digitale.
Se da un lato alcune parti del mondo si dedicano alla privacy come l’Europa e il suo GDPR, ci sono ancora molte nazioni, dalla Nord Corea al Venezuela alla Russia, che intervengono pesantemente nel violare la privacy degli utenti e il numero dei casi sta aumentando.
All’inizio di questo mese, ad esempio, l’assemblea nazionale del Vietnam ha obbligato le multinazionali ad aprire i loro archivi per poter accedere più facilmente ai dati personali dei loro clienti. E questo è un segno dei tempi.
Dal momento che la globalizzazione porta la tecnologia al servizio dei cittadini in ogni angolo del mondo, i regimi oppressivi stanno sfruttando appieno l’accesso ai dati personali per iniziative legislative, per la censura e l’arresto di disobbedienti e contestatori. Si tratta di un problema fondamentale che richiede una soluzione definitiva.
Ma com’è possibile garantire sicurezza a dati e interazioni online in un mondo dove queste sono per struttura tutto tranne che private? E anche trovando il metodo tecnico, come possiamo creare una piattaforma che sia in grado di operare fuori dal controllo dei governi?
Privacy e libertà in rete. Il fallimento delle reti sicure…
La risposta, non sufficiente, data finora, è stata quella delle tecnologie centralizzate per la creazione di reti basate sulla privacy. Un buon esempio di questo si è verificato in Russia, dove per anni i cittadini hanno utilizzato una Rete Virtuale privata (VPN) per le loro comunicazioni. Ma nel 2017 il presidente russo Vladimir Putin ha diramato una legge che restringe l’utilizzo degli anonimizzatori per adattare le infrastrutture agli standard imposti dal governo.
Questo significa che tutti i servizi che per anni hanno permesso lo scambio di informazioni a giornalisti, attivisti per i diritti umani, studenti e contestatori politici, sono stati annientati. Insomma il fallimento delle comunicazioni centralizzate.
Ma per fortuna, laddove la centralizzazione fallisce, la blockchain salva.
…e la nuova frontiera: la blockchain
La blockchain è un sistema di comunicazioni decentralizzato dove i dispositivi (detti “nodi”), scambiano dati, dove il trasferimento delle informazioni è preventivamente approvato da tutta la community e dove la transazione è tracciata in maniera immodificabile. È un sistema che vive da solo, senza bisogno dell’intervento di un’autorità superiore e per questo completamente libero.
Queste piattaforme possono essere criptate in tutti gli stadi del loro funzionamento per garantire che l’identità degli utenti non sia mai divulgata, nemmeno inavvertitamente, durante il trasferimento delle informazioni. In questo modo, nessuna regime oppressivo potrebbe domandare alla blockchain di consegnare gli accessi o i dati degli utenti perché non c’è nessuna entità che abbia l’effettivo controllo del sistema.
E’ la tecnologia alla base del funzionamento e dello scambio della moneta digitale Bitcoin, ma il sistema stesso della blockchain può essere applicato a qualsiasi altro aspetto della vita digitale.
Esistono in realtà esistono già adesso delle piattaforme basate sulla blockchain che permettono di eseguire interazioni, dai pagamenti, alla pubblicazione di notizie fino ai Social media, che sono effettivamente protetti da un intervento governativo.
In un’era dove le violazioni dei diritti umani stanno diventando sempre peggiori, la possibilità di avere a disposizione questi sistemi sta diventando una questione di vita o di morte per moltissime persone che vivono in paesi con condizioni restrittive.
Dalla comunità LGBT in Russia, alla Cina dove è proibito l’uso di Twitter fino ai giornalisti che lavorano in Turchia.
Ma, attenzione, questo è un problema che affligge tutti noi e non solo chi combatte ogni giorno per la libertà. È stato stimato che due terzi di tutti gli utenti del mondo sono stati in qualche modo coinvolti dalla censura governativa.
Più in generale i diritti politici e le libertà civili in tutto il mondo si sono deteriorate e hanno raggiunto il livello più basso negli ultimi decenni. Il livello di libertà è in continuo declino. Ecco perché dei miglioramenti basati su una blockchain anonimizzata possono essere così importanti.
In realtà ci sono pochi diritti umani così trasversali e importanti come la privacy. E se milioni di persone che vivono in governi oppressivi non possono esercitare i loro diritti questa nuova tecnologia potrebbe restituire ad internet quelle caratteristiche di completa libertà che erano tanto care ai padri fondatori del web.
Il nuovo sistema operativo mobile iOS 12 per iPhone, iPad e i dispositivi Apple è stato rilasciato con delle soluzioni di sicurezza e privacy abbastanza soddisfacenti. In altre parole: non sono moltissime, ma quelle presenti sono state pensate bene.
Apple è una delle aziende più in grado delle altre di introdurre sistemi di sicurezza nel grande pubblico. Fu Cupertino a sdoganare il riconoscimento delle impronte digitali TouchID, e sempre la Mela diffuse lo sblocco dello smartphone via riconoscimento facciale. Ok, esisteva già da prima, ma non efficiente come quello Apple, diciamocelo. Tanto che gli unici metodi per fregare Face IDfurono sviluppati da cervelloni, rari sulla terra.
Apple iOS 12: più aggiornamenti di sicurezza per tutti
iOS 12 conferma di aver pensato bene al discorso sicurezza e privacy.
La più interessante novità di sicurezza in realtà, non è stata pensata per la sicurezza. Tuttavia, iOS 12 è compatibile con tutti gli iPhone, iPad e iPod che hanno ancora iOS 11. E questo significa anche i vetusti iPhone 5S e gli iPad Air, ovvero “reperti archeologici” di 5 anni fa.
Perchè questa insolita compatibilità su vasta scala? perchè il consumo della batteria è un tema carissimo ai clienti della Mela, iOS 12 è stato sviluppato con il punto fermo di migliorarne la gestione e assicurare la compatibilità di iOS 12 con i dispositivi precedenti significa permettere a decine di milioni di utenti di aggiornare il sistema operativo, vederlo funzionare bene e godere della nuova gestione della batteria.
Questo fa bene alle performance, ma fa bene anche alla sicurezza: significa che gli aggiornamenti e gli update pensati per iOS 12 verranno diramati anche su un vasto numero di modelli precedenti. Chi usa i prodotti Apple, sa bene che di norma questo non avviene, e chi rimane indietro nelle versione del sistema operativo difficilmente riesce a stare al passo.
Insomma, due piccioni con una fava. Ed è la cosa che ci fa più contenti.
In generale, sembra che Apple, che prima costringeva a passare abbastanza rapidamente da un dispositivo più vecchio ad uno più nuovo attraverso aggiornamenti che lasciavano spietatamente indietro gli altri, abbia cambiato approccio. Il ciclo di vita dei prodotti è stato leggermente allungato, e i guadagni vengono recuperati ampliando le periferiche, come gli earPod.
Autenticazione a due fattori: l’autocompletamento
Un altro interessante elemento riguarda l’autenticazione a due fattori. Ormai da anni, i sistemi di sicurezza ci identificano e ci inviano un messaggio SMS su un dispositivo fisico che possediamo per verificare la nostra identità. Se fino a questo momento ci giungeva un messaggino e dovevamo frettolosamente ripetere le cifre di sicurezza nel form di registrazione o di acquisto, iOS 12 riceverà il messaggio e lo inserirà automaticamente nei campi necessari.
Insomma, farà tutto lui.
Per aumentare la durata della batteria hanno favorito la diffusione delle patch di sicurezza. Prendendo due piccioni con una fava, Apple migliora la sicurezza di iOS 12
Può sembrare cosa da poco, e invece non lo è: la scomodità e gli impicci sono i più grandi nemici della sicurezza, e aver semplificato questo piccolo gesto significa aver capito come ragiona la gente.
Inoltre, anche i produttori di terze parti potranno utilizzare i codici API forniti da Apple, e godere dello stesso sistema di “accelerazione” dell’autenticazione a due fattori, aumentando il numero di servizi che offrono all’utente questa comodità.
Durante la conferenza di presentazione è stato detto che per gestire le password “basterà chiedere a Siri“, il noto assistente vocale di Apple che partì dal telefonare ai nostri contatti e ora ci racconta pure le barzellette. La funzione non è stata descritta nei dettagli, ma con grande probabilità, significa che attraverso un comando vocale, potremo accedere al nostro password manager, che di norma ci impone di andare in Impostazioni> Account & Password > App & Website Password > iCloud).
Una scorciatoia vocale che permette di saltare dei passaggi, a volte frustranti da fare. Ovviamente, prima di utilizzare il password manager verrà richiesta una autenticazione attraverso l’impronta digitale o il nostro volto.
Il sistema anti tracciamento nel browser Safari e la gestione delle password
La parte restante dei miglioramenti di sicurezza risiede nella navigazione web.
Il primo punto è un aggiornato e migliorato sistema anti tracciamento della nostra navigazione, per rimanere al sicuro dagli inserzionisti pubblicitari più ficcanaso. Detta così sembra troppo bello e infatti lo è: non saremmo onesti nel dire che iOS 12 anonimizza gli utenti. Quello che è ragionevole pensare è che la nostra identità più profonda, come i dati biometrici o la posizione geografica, sia ragionevolmente protetta e i “pubblicitari” possano vedere solamente dati aggregati.
Un buon lavoro è stato fatto anche nella creazione delle password sicure: qualora venga richiesto dall’utente, il browser Safari sarà in grado di generare automaticamente una password “forte”, ovvero dotata di lettere, numeri e caratteri speciali e dunque difficile da indovinare, inserirla laddove ci serve e conservarla al sicuro nella nostra iCloud Keychain.
Il browser Safari integrato in iOS 12 integra un sistema anti tracciamento dei dati da parte degli inserzionisti pubblicitari. Non siamo all’anonimato, ma almeno i dati saranno aggregati
Carina, idea decisamente carina. Anche se il rischio è che l’utente, sapendo di dover ricordare una password difficile da memorizzare, scelga di non utilizzare il servizio e inserire la solita 123456. Ma questa non è colpa di Cupertino.
Ancora, il sistema di segnalazione delle password riutilizzate. Si tratta di un meccanismo per cui nel momento in cui utilizziamo la stessa password su due servizi diversi, uno degli errori fondamentali nella sicurezza informatica e che puntualmente facciamo tutti, il dispositivo ci segnalerà con una bandierina la parola d’ordine ripetuta, con la speranza di farci sentire gravemente in colpa e portarci all’utilizzo di password uniche per ogni accesso.
Un occhio all’USB, Facetime… e un giudizio finale
Apple completa la sua gamma di miglioramenti della sicurezza pensando alla connessione USB. Il sistema si chiama USB Restricted Mode, e prevede in sostanza che l’utente, qualora avesse una connessione USB in corso, debba sbloccare il telefono almeno una volta ogni ora per mantenerla attiva. Nei pensieri degli esperti Apple questo servirebbe ad impedire attività di spionaggio da parte di hacker o delle forze dell’ordine.
L’altro lato della medaglia è la connessione che si interrompe all’improvviso perchè puntualmente ti dimentichi di risvegliare il dispositivo e le relative imprecazioni.
Ma Apple non odia la polizia, anzi. Una funzione dedicata trasmetterà automaticamente la nostra posizione geografica alle forze dell’ordine, qualora dovessimo eseguire una chiamata d’emergenza.
Infine, tra le pieghe della presentazione si scorge anche una funzionalità che consente di eseguire videochiamate di gruppo con Facetime in modalità criptata, laddove prima la cifratura avveniva solo end-to-end, cioè fra due soli terminali.
Non possiamo certo dire che la sicurezza sia stata il pensiero principale degli ingegneri della Mela, e infatti il più importante miglioramento in questo senso è piuttosto una conseguenza di una ottimizzazione delle performance, ma le idee sono valide e ci è piaciuto molto l’approccio di rendere “comoda” la sicurezza. Dal punto di vista della protezione non possiamo non consigliare l’aggiornamento.
Il popolo dei videogamer che aspetta l’uscita su Android di Fortnite, il celebre videogioco di sopravvivenza tanto bello da causare dipendenza, viene preso in giro alla grande da false versioni del gioco. E chi fa perdere tempo ai gamer, stressandoli, ci sta guadagnando tantissimo.
La Epic Games, produttrice del gioco Fortnite, rilascerà nel corso di questa estate la versione per Android e da mesi il mondo dei videogiochi non fa che parlarne. Primi test, trucchi per giocare meglio e previsioni sulle prossime release attirano milioni di appassionati in tutto il mondo.
Ma i ricercatori di Malwarebytessi sono accorti che oltre al download diretto che sarà disponibile sul sito del produttore e su Play Store, esistono migliaia di video di Youtube, che presentano novità sul gioco, mostrano degli annunci che invitano a scaricare il gioco in anteprima.
Cliccando sul link si scarica una applicazione con un logo altamente credibile di Fortnite, seguito dal marchio dell’azienda e dalla sigla ufficiale del videogame. Il problema è che ad un certo punto l’applicazione richiede di verificare che tu non sia un robot, in un inglese francamente stentato, e invita a provare che tu sia un umano eseguendo un’azione complessa. Nel caso specifico, si tratta di scaricare una seconda applicazione gratuita.
Per fortuna, l’utente viene redirezionato sullo store ufficiale Google Play e l’applicazione da scaricare è legittima, a volte addirittura riguarda la sicurezza dello smartphone. Il punto è che a prescindere da quante app si scarichino per dimostrare di essere “umani”, in realtà il gioco non viene mai sbloccato perchè fin dall’inizio è stata tutta una montatura.
In tutto questo, i videogamer si arrabbiano e perdono tempo, riempiendo i social di critiche e lamentele, o ancora chiedendo nei gruppi Facebook come sbloccare l’applicazione, mentre a guadagnarci sono gli inserzionisti che hanno messo l’annuncio sotto i video di YouTube da cui tutto parte. E loro si stanno facendo i milioni.
Purtroppo, secondo statistiche recenti, ad ogni uscita di un videogioco si scatenano meccanismi e scenari simili a questo, e per comprendere la gravità del fenomeno basti pensare che i procacciatori di giochi falsi o di versioni scaricabili “prima del lancio ufficiale” guadagnano quasi quanto i legittimi produttori dei videogiochi.
Quando si dice che la privacy non esiste più, è perfettamente vero. E quando si dice che la privacy è diventata un lusso, è anch’esso verissimo. Ed esistono persone in grado di spendere milioni di euro pur di vivere una vita in totale riservatezza.
Ormai dobbiamo arrenderci alla dura realtà: i consumatori della classe media e i più poveri in particolare hanno dovuto vendere il loro diritto alla privacy in cambio della connessione ad internet e all’utilizzo dei social network, perchè tutto ha il suo prezzo.
E le persone sono ben contente di fare questo scambio. Un sondaggio della Intel Security ha scoperto che il 77% delle persone sarebbe felice di vendere tutti i suoi dati personali in cambio di sconti per le ricariche telefoniche. Come risultato il tracciamento dei nostri dati è ormai continuo.
I produttori di veicoli installano dei sistemi per il tracciamento dei nostri percorsi, i dispositivi indossabili controllano la nostra attività fisica e i nostri parametri biologici collegandoli spesso alle nostre preferenze alimentari.
Ma esistono persone, ovviamente le più ricche, che sono in grado di spendere migliaia e anche in milioni di euro per il lusso di vivere nella più completa privacy.
Privacy in città. Anonimi per il catasto
Ad esempio, a Londra è possibile pagare il governo per non risultare nei registri. Nella capitale britannica un gruppo di poco più di 200 ricchi cittadini ha scelto di pagare una tassa annuale di 218.200 sterline in cambio dell’occultamento dei dati catastali delle loro mega ville presso gli uffici comunali. E sempre in Inghilterra il discorso si sta espandendo oltre i limiti del mercato immobiliare.
Grazie alle nuove legislazioni su internet gli inglesi stanno covando l’idea di far pagare delle tasse verso i provider e i fornitori di servizi internet per evitare che i dati degli utenti vangano venduti a terze persone.
Le case di specchi contro gli spioni
Se siete abbastanza ricchi potete rivolgervi a degli architetti per costruire delle case invisibili. JaK Studio, una azienda specializzata, è in grado di inventare dei metodi tecnici per creare delle porzioni di casa che possono apparire o sparire quando lo desideriamo.
Uno dei metodi utilizzati è quello di installare degli specchi personalizzati per riflettere le immagini della propria abitazione e alterarne la forma. Tutto questo per non far capire ai vicini l’esatta conformazione della propria dimora e per fuorviare le riprese fotografiche aeree.
Un’oasi nascosta a Google Maps
Se volete disfarvi una volta per tutte di Google Maps e delle fotografie alla vostra abitazione potete trasferirvi in una comunità nascosta. Ce n’è una a Los Angeles chiamata Hidden Hills, a cui hanno già aderito il cantante Justin Bieber e la showgirl Kim Kardashian oppure la Three Rivers Recreation Area nell’Oregon.
Si tratta di una delle poche zone della Terra dove vengono proibite le fotografie da parte della macchinina del Google Street View: niente immagini delle strade e nessun tipo di ripresa dall’alto. I prezzi di una proprietà in questi angoli invisibili a Google, partono dai 5 milioni di dollari.
Investigatori di privacy
Se qualcuno accede alle vostre informazioni personali o pubblica qualcosa di voi su internet, potete pagare anche una compagnia per individuare il criminale. Queste aziende promettono di controllare la vostra identità digitale eliminando qualsiasi tipo di pubblicità negativa e prevenendo ogni tipo di scandalo anche con metodi non proprio legali. Aspettatevi di pagare dai 50 ai 300 mila dollari per progetto, oltre ad un abbonamento mensile per il mantenimento del servizio.
I social network nascosti
Se Facebook, Tinder o Instagram sono troppo “pubblici” per voi, potete pagare per entrare in un social network privato, destinato agli ultraricchi. Per esempio, una versione alternativa di Instagram è “Rich kids“, che mette ogni tipo di foto o di selfie al sicuro, visibile solamente a dei contatti selezionati, per la modica cifra di 1000 dollari al mese.
La domanda è: quanto paghereste, se aveste i soldi, per proteggere la vostra privacy?
"Utilizziamo i cookie per personalizzare contenuti ed annunci, per fornire funzionalità dei social media e per analizzare il nostro traffico. Condividiamo inoltre informazioni sul modo in cui utilizza il nostro sito con i nostri partner che si occupano di analisi dei dati web, pubblicità e social media, i quali potrebbero combinarle con altre informazioni che ha fornito loro o che hanno raccolto dal suo utilizzo dei loro servizi.
Cliccando su “Accetta tutti”, acconsenti all'uso di tutti i cookie. Cliccando su “Rifiuta”, continui la navigazione senza i cookie ad eccezione di quelli tecnici. Per maggiori informazioni o per personalizzare le tue preferenze, clicca su “Gestisci preferenze”."
Questo sito web utilizza i cookie.
I siti web utilizzano i cookie per migliorare le funzionalità e personalizzare la tua esperienza. Puoi gestire le tue preferenze, ma tieni presente che bloccare alcuni tipi di cookie potrebbe avere un impatto sulle prestazioni del sito e sui servizi offerti.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_logged_in
Used to store logged-in users.
Persistent
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
_gac_
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
X Pixel enables businesses to track user interactions and optimize ad performance on the X platform effectively.
Our Website uses X buttons to allow our visitors to follow our promotional X feeds, and sometimes embed feeds on our Website.
2 years
guest_id
This cookie is set by X to identify and track the website visitor. Registers if a users is signed in the X platform and collects information about ad preferences.
2 years
personalization_id
Unique value with which users can be identified by X. Collected information is used to be personalize X services, including X trends, stories, ads and suggestions.
2 years
Per maggiori informazioni, consulta la nostra https://www.alground.com/site/privacy-e-cookie/