L’altro giorno ho provato a postare sul mio account Facebook una considerazione.
Ho parlato dello scandalo di Cambridge Analytica, cioè della scoperta che il piccolo tastino che consente di entrare in vari servizi online attraverso il proprio account social, per risparmiare tempo, girava verso terzi una quantità spaventosa di dati personali. In maniera certamente aggressiva, tanto che a Palo Alto si sono affrettati a rassicurare gli utenti e a “tirarsi fuori”.
Ho spiegato alle mie cerchie di amici, che in realtà era abbastanza ovvio che a fronte di un servizio gratuito si commerciassero i dati, e che esiste un altro giochino che sta facendo incetta di informazioni. Sono quei piccoli sondaggi: “Quali amici ti vorrebbero sposare?”; “Chi ti vuole baciare?” da ricondividere sulla propria bacheca. Un giorno faranno finta di accorgersene per caso, con un buon accompagnamento di indignazione, ma il mercimonio di informazioni personali è attivo più che mai.
Quello che mi ha stupito, sono state le risposte: “Che se li tengano i miei dati. Se vogliono anche le foto di quello che mangio, facciano pure”. O ancora: “Dei nostri dati sicuramente non se ne fanno niente, li possono usare solo come soprammobili a raccogliere polvere”.
Quindi, nessuno se ne importa.
In realtà avrebbero anche ragione: Facebook è un servizio enorme, gigantesco, ed è anche giusto che con i nostri dati, che se ci vengono prelevati nessuno muore, diventino miliardari.
Ma il punto è: il rischio è veramente zero?
Assolutamente no, il rischio c’è, eccome.
Ognuno inscatolato nel suo mondo
Il problema sta nella combinazione di due elementi.
Il primo è la quantità, qualità e coerenza dei dati personali. Non sanno solamente chi siamo, ma sanno cosa pensiamo, cosa ci piace e non ci piace, a quali eventi partecipiamo, su cosa siamo d’accordo e su cosa litighiamo. A che orientamento politico apparteniamo, chi sosteniamo e chi critichiamo. Sono come un amico, o un familiare che conosce molto bene i nostri gusti.
Il secondo elemento è: Facebook può farci vedere quello che vuole. Può indirizzare gli argomenti della nostra bacheca, filtrare quello che dicono gli amici, collegarci e suggerirci gruppi di discussione. Può farci vedere solamente una parte della realtà.
Voi direte: ma mica mi faccio influenzare. Io vado a controllare anche fuori da Facebook. Sarà, ma dal momento che esiste il fenomeno delle fake news, e che oltre il 90% di queste potrebbero essere scoperte solamente facendo una ricerca all’esterno di Facebook, evidentemente la stragrande maggioranza della gente non esce dal social.
Nessuno ha voglia di controllare, di verificare. Le informazioni giungono rapidamente, corredate da commenti con cui siamo d’accordo o in disaccordo, vogliamo partecipare subito alla discussione.
Non possiamo e non vogliamo controllare. Vogliamo esserci, quello è l’importante.
Per cui, se uniamo la profilazione dei nostri gusti, al filtraggio delle informazioni, esce fuori la possibilità di creare un mondo personalizzato e condizionato per spingerci ad aderire a qualcosa, ad una idea, ad una causa. Su Facebook tutti adorano sostenere delle cause.
Un esempio su me stesso: sono appassionato di storia dell’antica Roma. Facebook, vogliamo credere in modo del tutto ignaro, mi ha suggerito molto spesso dei gruppi di revisione storica, di riconsiderazione del fascismo, de “la storia la scrivono i vincitori”. Ho conosciuto persone a me affini che erano neofasciste convinte.
Se non avessi anni di studio alle spalle, probabilmente ora riterrei che il fascismo è il movimento politico più simile all’Impero Romano.
Questo è il vero pericolo: più dei dati, delle pubblicità mirate, delle catene di Sant’Antonio. Essere in grado di fare la cosa più potente al mondo.
Inculcare delle opinioni, facendo credere alla gente che siano idee loro.
Diciamoci la verità: le aziende hanno sempre dato al trattamento dei dati e alla “protezione” dei dati una priorità molto bassa, perché si accorgono molto bene dei costi ma non percepiscono subito i vantaggi. Ma a cambiare la situazione sono giunti i regolamenti europei (il GDPR) che hanno promesso delle multe salatissime contro il responsabile del trattamento dei dati.
Le imprese, stavolta attente, per non dire spaventate, come non mai, vogliono sapere come gestire, trattare e proteggere i dati personali per evitare pesantissime punizioni. La nostra guida sul trattamento dei dati e sulla loro protezione in ambito aziendale ha esattamente questo scopo: insegnarvi, rapidamente e anche se non siete esperti, a mettervi in regola per evitare multe.
Anche se sono insegnamenti teorici è importantissimo che partiate con il piede giusto capendo che cos’è un dato personale.
Si tratta di una informazione relativa ad una persona.
Un tempo, nel 1995, agli albori di questo tipo di regolamenti, il dato personale era considerato il nome e il cognome, l’indirizzo di residenza o l’indirizzo mail. Dal 2016 in poi si considerano dati personali anche elementi tecnici come l’indirizzo IP del proprio computer o il MAC address che identifica uno smartphone.
Come salvarti dalle multe del GDPR: impara come si classificano i dati personali
Il dato personale quindi è qualsiasi cosa, anche un numero digitale, che permette di identificare una persona.
Esistono quattro tipi di dati personali, che il GDPR considera nel trattamento dei dati. I dati Provided, Observed, Derived e Inferred.
I dati Provided – E’ la forma più semplice. Si tratta di dati forniti consapevolmente dall’utente. Un cliente nel vostro e-commerce compra un prodotto e scrive i suoi dati personali per completare l’ordine. E’ un esempio di dato “Provided“.
I dati “Observed” – Si tratta di una situazione in cui il titolare di una attività utilizza degli strumenti, come Google Analytics, Piwik o altri software simili, per raccogliere dati degli utenti sul suo sito. Per esempio l’indirizzo Ip, la loro provenienza geografica, le pagine che hanno visto, che browser hanno usato.
E’ una raccolta di dati personali fatta autonomamente dal titolare che l’utente in un certo senso “subisce”. Per questo è stato inventato il foglio del trattamento dati, che tutti i siti devono inserire all’interno delle loro pagine legali. Questi sono i dati “Observed”.
I dati “Derived” – In questo caso si prendono dei dati appartenenti a degli utenti, si analizzano, e da questa analisi si deducono o calcolano altri dati. Ad esempio, se in un sito di e-commerce vediamo le abitudini di acquisto dei nostri utenti, i prodotti che comprano e i prezzi che pagano, ne deriviamo delle ragionevoli fasce di reddito. Capiamo quindi che il 20% dei nostri utenti ha un reddito medio alto. Questo è un esempio di dato derivato.
4 tipi di dati. Provided, quelli forniti spontaneamente, Observed, quelli prelevati con i software, Derived, calcolati da altri dati e Inferred, realizzati su base statistica
I dati “Inferred”- Qui abbiamo dei dati aggregati che vengono analizzati e sui quali si fanno delle previsioni statistiche.
Ad esempio studiamo l’età, il numero di incidenti e di multe prese da un guidatore per stabilire il suo rischio stradale, sulla base del quale fargli una polizza assicurativa. Questo è un esempio di dato “Inferred”. Questi dati sono quelli più aleatori, perché si tratta di informazioni calcolate.
Una considerazione originale, è che di tutti questi dati, quelli che potrebbero sembrare più importanti sono quelli economici, come per esempio il PIN di una carta di credito, il numero di conto corrente, o un IBAN.
In realtà è vero che sono legati al denaro, ma sono dati modificabili. Invece i nostri gusti, le nostre abitudini di navigazione e addirittura i dati biometrici di uno Smartwatch o di un’applicazione per la ginnastica, sono molto più preziosi perché completamente o molto difficilmente modificabili.
I soggetti e i responsabili del trattamento dati
Le persone che devono trattare i dati vengono definite in maniera precisa dalla normativa GDPR.
Il primo è il titolare del trattamento. E’ la persona che deve decidere come si trattano i dati, che ha il compito di controllare che le norme vengano rispettate e vigilare che sulla protezione dei dati. Non è necessariamente un esperto che deve entrare nel merito tecnico della questione, ma è quello che decide la politica aziendale sul trattamento dei dati.
Il titolare, attraverso una nomina scritta, un contratto o un altro atto con valore giuridico, deve nominare un responsabile del trattamento dei dati. Questa seconda persona di norma è quella che ha le competenze tecniche per gestire le informazioni e sceglie anche i programmi o i servizi da usare.
Una novità introdotta dal GDPR europeo, la nuova normativa che aggiorna in maniera importante le regole UE, introduce per la prima volta la figura di uno o più sub-responsabili al trattamento, nominati dal responsabile, anche in questo caso tramite un documento ufficiale.
Come organizzare un trattamento dei dati che piaccia alla legge
Ora che abbiamo capito cosa sono i dati personali e chi li deve gestire, impariamo come definire una procedura di trattamento delle informazioni.
Il primo elemento da cui partire è un’analisi della natura dei dati e del contesto aziendale, assieme alle finalità di questo trattamento.
Ad esempio un’azienda che conserva i dati dei clienti da richiamare per vendere dei mobili, avrà dei dati di una natura e con una finalità diversa rispetto ad un portale di affiliazione che vuole rivendere i dati ad aziende terze o che fa pubblicità mirata.
Quindi dovete stabilire quali dati avete, e a cosa vi servono.
Stabilito questo, potrete definire nel concreto la procedura del trattamento dei dati.
Questo trattamento consta di una serie di fasi identificabili che sono:
la raccolta
la registrazione
l’organizzazione
la strutturazione
la conservazione
la modifica
l’estrazione
l’uso
la comunicazione a terzi
il raffronto
la limitazione
la cancellazione.
Dovrete quindi fare un lavoro interno all’azienda, per arrivare a stabilire esattamente ognuno di questi punti, come viene fatto, da chi e con quali servizi. Quando avrete chiaro come si svolge questo processo, con quali strumenti tecnici lo farete, con quali software e con quali tempi, avrete definito la vostra modalità di trattamento dei dati.
Non possiamo dirvi a priori qual è la procedura migliore, ma se volete essere il più certi possibile che la vostra modalità di trattamento dei dati sia gradita dal regolamento, potete seguire quattro principi sulla protezione dei dati che vi mettono al sicuro.
Più il trattamento dati raccoglie dati utili, separati dalle identità, cifrati e anonimizzati, più siete sicuri di non poter violare le norme del GDPR
Minimizzazione – Per minimizzazione si intende la raccolta dei dati strettamente necessari allo scopo che avete. Evitate di raccogliere più dati di quelli che vi servono: già questo è un buon punto di partenza.
Pseudonimizzazione – Si tratta di un processo in cui i dati strettamente personali di un utente vengono separati da quelli utili a comprendere il suo comportamento.
Per esempio, se degli utenti del vostro e-commerce ignorate le vie dove abitano o il loro indirizzo IP, ma guardate semplicemente che cosa hanno acquistato nel tempo, state pseudonimizzando i dati.
La legge del GDPR non considera questi dati come “anonimi” perché mettendoci un po’ di buona volontà si possono “ricollegare” i dati all’identità. Però più tempo ci vuole per riunire e ricostruire i dati, e più i dati sono pseudonimizzati. E tanto più riuscite ad operare questa pseudonimizzazione, tanto più vi avvicinate alle norme.
Cifratura – La cifratura dei dati, operazione che rende i dati personali illeggibili al di fuori della vostra azienda, è una soluzione fantastica. Perché secondo la legge, in caso di violazione o furto dei dati, se questi sono cifrati, l’azienda non è tenuta ad informare gli interessati. E questo può risparmiarvi un grande lavoro e un danno di immagine notevole.
Anonimizzazione – Anonimizzare i dati significa prelevare degli elementi a voi utili ma scollegarli completamente e in maniera definitiva dalle informazioni personali.
In questo caso non è più possibile risalire, in nessun modo alla identità. E il bello è che se i vostri dati sono anonimi, e le persone non sono più identificabili, le norme in materia di protezione dei dati non sono più applicabili.
Riassumendo, quanto più prelevate i dati strettamente necessari a quello che vi serve, quanto più questi sono separati dalle identità, cifrati o addirittura anonimi, tanto meno come responsabili del trattamento dei dati, correrete rischi di violare la normativa.
Un punto importante: la gestione del rischio
Fino a questo punto, abbiamo spiegato come elaborare un trattamento dei dati quanto più sicuro dalle multe.
Ma il legislatore del GDPR ha scritto la normativa con una finalità ben precisa.
Vuole che le aziende si rendano conto che trattare i dati comporta dei rischi e che i titolari siano attivi nella protezione dei dati. Per questo motivo, ad un trattamento adeguato dovete aggiungere la consapevolezza del rischio e dei metodi per prevenirli.
L’azienda normalmente considera rischioso tutto quello che blocca la sua attività e il suo guadagno, ma la legge, in un senso più ampio, considera il rischio qualcosa di più attinente alla violazione del diritto e della libertà del cittadino.
I rischi principali relativi ai dati sono:
la distruzione
la perdita
la divulgazione non autorizzata
l’accesso accidentale o illegale da parte di persone non previste
Se volete essere sicuri di considerare i rischi in maniera adeguata potete fare riferimento ad un elenco che viene fuori spulciando la legge.
Il registro dei trattamenti – Innanzitutto dovete tenere un registro dei trattamenti, cioè dovete tenere traccia di come i dati sono stati trattati e gestiti nell’azienda.
Il DPO – Dovete nominare un DPO, Data Protection Officer, una persona specifica che si occupa solo della protezione dei dati, anche questa va nominata con un atto scritto.
Formazione del personale – E’ inutile che in azienda ci sia un solo esperto di questo argomento, e una pletora di dipendenti completamente ignari delle regole di sicurezza. Quindi investite qualche ora per formare il personale e soprattutto rendetelo dimostrabile con un attestato, o una certificazione di qualche azienda esterna.
All’interno di una legge collegata con il GDPR c’è anche un interessante elenco di adempimenti per la gestione del rischio che dovreste seguire per essere ragionevolmente sicuri di non poter essere multati.
Vietare alle persone non autorizzate l’accesso alle attrezzature utilizzate per il trattamento
Impedire che i supporti di dati possono essere letti, copiati, modificati o asportati da persone non autorizzate
Impedire che i dati personali siano inseriti senza autorizzazione
Impedire che i dati personali conservati siano visionati, modificati o cancellati senza autorizzazione
Impedire che persone non autorizzate utilizzino sistemi di trattamento automatizzato mediante attrezzature per la trasmissione di dati
Garantire che le persone autorizzate a usare un sistema di trattamento automatizzato abbiano accesso solo ai dati personali cui si riferisce la loro autorizzazione
Garantire la possibilità di verificare quali dati personali sono stati introdotti nei sistemi, il momento della loro introduzione e la persona che l’ha effettuata
Impedire che i dati personali possono essere letti, copiati, modificati o cancellati in modo non autorizzato durante i trasferimenti di dati personali
Garantire che in caso di interruzione, i sistemi utilizzati possano essere ripristinati
Garantire che eventuali errori di funzionamento siano segnalati e che i dati personali conservati non possano essere falsati da un errore di funzionamento
Mettete alla prova il vostro trattamento dati
Come fate a sapere che il trattamento dei dati che avete organizzato e che le misure per la protezione dei dati siano adeguate? Dovete controllare che il risultato del vostro lavoro rispetti una serie di ideali che la legge considera importanti.
Riservatezza – I dati devono essere protetti. Avete delle soluzioni, dei programmi, dei software, anche online, che proteggano i dati?
Integrità – Durante il trattamento, i dati rimangono integri? si perde qualcosa? è possibile che nel trasferire un file Excel con i dati, magari cambiando nel formato, si perdano degli elementi?
Dovete sviluppare delle misure per prevenire i rischi e un documento che lo dimostri. Così rientrerete nelle norme ed evitate le sanzioni
Disponibilità – La possibilità di accedere ai dati. Quanto è facile accedere ai dati? Se solamente il responsabile del trattamento dei dati è in grado di accedere alle informazioni, questi non sono molto disponibili. Se sono registrati su una pennetta USB e solo il titolare conosce la password, questi non sono ragionevolmente disponibili. Verificate che sia possibile raggiungere le informazioni in maniera abbastanza veloce.
Resilienza– La resilienza è la capacità di reagire ad eventi imprevisti. Immaginate un attacco hacker, un imprevisto in azienda o una richiesta massiccia di modifica dei dati. Sapete chi chiamare? siete organizzati? Quanto tempo ci mettete per rispondere ad un evento imprevisto?
Ripristino – Immaginate che per qualche motivo i vostri dati vengano perduti. Avete una copia di backup? Esiste un modo di recuperarli? Se il computer su cui sono registrati esplode, avete perso tutto?
GDPR: il documento di previsione d’impatto, l’asso nella manica
Tutto questo importante lavoro aziendale non deve essere solo svolto ma deve essere anche registrato.
Dovete essere in grado di dimostrare tramite un documento che vi siete preoccupati del trattamento dei dati personali. Questo documento si chiama “Valutazione di impatto”
La legge prevede che si scriva questo report nel caso in cui si introducano delle nuove tecnologie in azienda, se si fa una profilazione particolarmente invasiva degli utenti, o se si raccolgono dati su vasta scala, ma noi vi suggeriamo di preparare comunque una valutazione di impatto.
Serve a dimostrare che avete pensato ad una strategia per fare bene le cose. E può esservi molto utile in caso di contestazione. All’interno di questo documento bisogna inserire
Descrizione dei trattamenti previsti e delle finalità
Valutazione dei rischi correlata alla realtà della vostra azienda
Misure di sicurezza previste
Tenete il documento aggiornato, sarà un asso della manica che potrete esibire per dimostrare la vostra buona fede nella protezione dei dati.
Il trattamento dati con il GDPR. E se le cose vanno male?
Nonostante tutti i vostri sforzi può essere che si verifichi una violazione dei dati. Uno di questi casi è il data breach. Ovvero quando un hacker buca il vostro sito e riesce ad accedere ai dati dei vostri clienti o ad altre informazioni sensibili.
In questo caso non vi venga minimamente in mente di tenere la cosa riservata: è estremamente rischioso. La legge prevede che entro 72 ore, notifichiate al Garante della privacy l’esistenza di un data breach nei vostri confronti.
In realtà la legge non ha ancora spiegato nei dettagli come bisogna fare questa comunicazione. E’ altamente probabile che il Garante si pronuncerà. Ma nel frattempo, registrate in ogni modo la volontà di comunicare al Garante il fatto.
Di norma, il titolare va nei guai se non ha stabilito delle regole, mentre il responsabile se non le ha applicate
Registrate le mail che gli spedite, inviategli il documento con la valutazione di impatto, registrate le telefonate che fate. Cercate di testimoniare la vostra piena volontà di rispettare la legge e comunicare la violazione dei dati personali.
Ovviamente la violazione dei dati comporta delle responsabilità. Concludiamo la nostra guida con il concetto di “Accountability”. Un termine inglese, inserito all’interno del GDPR, che sta ad indicare la responsabilità, e anche la punibilità di coloro che non si adeguano.
Le responsabilità. Chi finisce nei guai e quando?
Semplificando di molto la legge: il titolare del trattamento dei dati finisce nei guai se non ha mai previsto delle misure di protezione, non ha mai nominato un responsabile e se non è in grado di dimostrare la sua volontà di seguire la norma con dei documenti. In questo caso, risponde in proporzione al danno causato, che viene quantificato dal Garante.
Il responsabile del trattamento dei dati va nei guai nel momento in cui o non ha seguito le regole che sono stabilite dal titolare o se le ha seguite in maniera diversa da quanto scritto.
In alcuni casi, il titolare, il responsabile e i subresponsabili possono andare nei guai contemporaneamente se il titolare ha dato istruzioni insufficienti, il responsabile le ha attuate male e le ha fatte attuare in maniera insufficiente anche ai suoi subresponsabili.
In questo caso, sono tutti punibili in maniera uguale e compartecipano al risarcimento del danno, sempre stabilito dal Garante.
Accade nei posti più impensati: nei giochi online, sotto richieste di lavoro, dietro vecchie mail con improbabili proposte. Internet è un mondo magnifico per chi vuole riciclare denaro online, perchè le possibilità si moltiplicano, le identità si camuffano e i soldi girano non visti. Alground ha identificato in un report i principali modi con cui la criminalità organizzata mondiale ricicla soldi sporchi.
Di statistiche sul tema non ce ne sono molte: in fin dei conti il mondo virtuale è immenso e le transazioni giornaliere centinaia di milioni. Questo non significa però che sia impossibile ricostruire il modo in cui questi processi di riciclaggio vengano condotti nonostante l’ovvia anonimità vigente in rete. Attraverso una capillare ricerca su forum più o meno specializzati diversi dei nostri analisti sono riusciti ad identificare quali siano i metodi più usati per riciclare denaro su internet e come spesso e volentieri utenti ignari si trovino intrappolati in una rete criminale senza nemmeno sapere di esserne parte.
L’alleato numero uno per riciclare denaro online: i videogiochi
Il grande problema dei criminali che guadagnano soldi da attività illecite è quello di riciclare i loro proventi e farli passare per denaro ottenuto onestamente tramite attività regolari.
Al primo posto come strumento di riciclaggio ci sono i giochi online di tipo multiplayer. Queste piattaforme si prestano bene allo scopo perchè si basano sulla possibilità di convertire crediti di gioco in denaro reale.
I delinquenti aprono diversi account, ci associano diverse carte ricaricabili e comprano con i soldi sporchi dei crediti di gioco. Possono usare carte prepagate, carte rubate o denaro Bitcoin già in formato digitale. Una volta che il denaro sporco è stato convertito in crediti, i criminali raggiungono i forum o le piattaforme di scambio tra i giocatori e rivendono a ragazzini inesperti i crediti in cambio di denaro reale, in modo da riavere a loro disposizione i soldi, ma stavolta da una transazione completamente lecita.
Dietro alla compravendita di crediti di gioco si nasconde molto spesso una complessa attività di riciclaggio di denaro online
Per abbreviare i tempi, vista la fatica necessaria a trovare i singoli giocatori che si prestino inconsapevolmente al riciclaggio, accade talvolta che i criminali vendano interi stock di crediti di gioco a piattaforme apposite che gliele pagano subito e che poi le rivenderanno ai singoli player, anche se in questo modo il denaro si svaluta molto.
Su un forum russo, un utente spiega. “Mio figlio ha venduto 60mila chili di oro per il videogioco World of Warcraft ad una piattaforma che gli ha pagato 70 dollari al chilo. Sul suo account Paypal ho visto accreditargli 5.600 dollari“.
È importante comprendere che in questo tipo di gaming online si gioca su server che danno modo di incontrare persone provenienti da qualsiasi parte del mondo, il che consente di eseguire gli scambi con giocatori e piattaforme in nazioni molto poco controllate, come tutto l’est Europa, senza che nessuno possa essere identificato.
Il vecchio Second Life e ora il popolarissimo World of Warcraft sono le due piattaforme più colpite da questo fenomeno, anche se ovviamente le aziende che sviluppano questi giochi sono totalmente estranee a queste attività criminali.
Il Micro riciclaggio tramite PayPal e le carte di credito virtuali
Un’altra formula spesso usata per riciclare denaro tramite la rete è quella del micro-riciclaggio attraverso account PayPal: questo consente ai criminali di non essere rintracciati e scoperti perché il lavoro “sporco”, senza che ne siano coscienti, riesce a passare inosservato.
Paypal è perfetto per attivare dei meccanismi di micro riciclaggio: anche se gli account vengono limitati, alcune funzioni come quella per il rimborso, continuano ad essere utili ai criminali
Non è una novità che PayPal sia uno strumento finanziario utilizzato per eseguire pagamenti di servizi o beni che nelle mani “giuste” possa rappresentare un mezzo importante per la pulizia di piccole cifre nonostante la presenza di procedure antiriciclaggio in vigore.
Quando si tratta di riciclare piccole cifre, derivanti dal furto di uno smartphone o dal prosciugamento di una carta prepagata, i criminali offrono di accreditare i soldi su un account Paypal pulito giustificandolo come acquisto di un normale prodotto che fanno finta di ricevere. Sembra così che il denaro non sia più nelle mani del criminale, ma in realtà il destinatario dei soldi utilizza la carta Paypal per ritirare il denaro contante presso uno sportello bancomat e restituisce i soldi al delinquente, trattenendosi una parte per il disturbo.
Per cifre più grosse, i criminali consegnano il denaro a dei soci che glieli restituiscono sotto forma di microtransazioni per abbonamenti a film, consegna di prodotti o ricariche telefoniche, che giustificando agli occhi della legge il possesso del contante. Anche nel caso in cui Paypal sospetti qualcosa e limiti gli account, nell’80% dei casi rimane attiva la funzione di rimborso, che consente comunque di continuare a movimentare denaro.
Anche le carte di credito virtuali stanno conquistando un posto di tutto rispetto tra le metodologie di riciclaggio utilizzate: questo perché possono essere caricate attraverso account bancari compromessi ed essere utilizzate per ricaricare account Paypal. Si tratta di un metodo con pochissima tracciabilità, che in caso di indagine porta a scoprire al massimo, il titolare del conto bancario derubato e non l’identità dell’hacker.
Le piattaforme per trovare freelancer: un altro paradiso per i criminali
Quello delle “offerte di lavoro” è senza dubbio il metodo più interessante a livello sociale tra quelli utilizzati dai cyber criminali per ripulire il proprio denaro.
Un metodo basilare è aprire un account presso la nota piattaforma Freelancer, che consente di aprire dei progetti di lavoro, individuare personale che li realizzi ed eseguire il pagamento della prestazione all’interno del sito stesso. Nel caso del riciclaggio di denaro, si apre un account, si avvia un progetto e si depositano dei fondi a disposizione dei freelancer che accetteranno il lavoro.
Si apre un secondo profilo Freelancer falso, come se si fosse un dipendente, e si fa una offerta per lavorare per il proprio stesso progetto. Dall’altro lato si accetta e si trasferiscono i soldi al proprio alter ego. Il possesso del denaro viene così giustificato come prestazione lavorativa, e si può poi trasferire il tutto verso un conto bancario o un Paypal.
In alternativa, se il quantitativo di denaro è maggiore, si coinvolgono terzi. Si spiega a qualcuno che, in qualità di datore di lavoro, si ha un problema nel ricevere i pagamenti dai propri clienti e si chiede di fare da tramite con un account Paypal, invitando “l’uomo in mezzo” a trattenere una percentuale su ogni transazione per il servizio svolto.
Sebbene l’intera presentazione dell’offerta di impiego dovrebbe far riflettere l’utente e tenerlo lontano da simili opportunità, molto spesso peccando di leggerezza lo stesso si mette, ignorando i pericoli, al servizio di delinquenti informatici perché bisognoso di soldi.
Piattaforme per trovare dipendenti, come Freelancer, sono infestate da falsi account sfruttati per giustificare il possesso di denaro illecito con normali remunerazioni a collaboratori
Piattaforme come Freelancer and Fiverr hanno il loro bel da fare nel combattere contro i riciclatori di denaro: in particolare quest’ultima è frequentemente usata per la creazione di account fake con i quali “comprare” servizi altrettanto falsi e di conseguenza ripulire grandi somme di denaro attraverso piccoli trasferimenti su differenti account.
Questo tipo di riciclaggio, sfruttando gli utenti o servizi apparentemente innocenti nella loro natura è uno degli approcci “nuovi” più utilizzati.
Si tratta di un’evoluzione delle classiche truffe via e-mail che ormai grazie alla preparazione dei servizi di posta elettronica contro lo spam ed alla conoscenza man mano acquisita dagli utenti stanno divenendo sempre meno fruttuose.
Viene superato anche il meccanismo di riciclaggio del denaro tramite conti bancari, in quanto tra account Paypal e Bitcoin è possibile eseguire tutto il lavoro appoggiandosi solamente al mondo virtuale.
Il vecchio metodo: le truffe via mail
Le truffe via e-mail, come anticipato, stanno scemando in efficacia. Tuttavia hanno subito un’evoluzione nel corso del tempo: quelle che una volta erano richieste di denaro per sbloccare grandi cifre ed ottenerne altre in cambio si sono trasformate, sfruttando comunque le fantomatiche figure di nobili africani ed ereditiere di varia origine, in richieste di passaggi di denaro su account PayPal per trasferimenti con tanto di percentuale da ottenere che puntano alla pulizia dello stesso portando i soldi dalla loro posizione originaria al paese della persona che riceve il messaggio.
I cartelli della droga colombiani sfruttano spesso la rete per ripulire i soldi derivanti dalla vendita di stupefacenti negli USA
Se non si controlla con regolarità la propria cartella spam non si ha la possibilità di accorgersene e questo racconta come, fortunatamente, i vari servizi di posta elettronica stiano migliorando la gestione delle minacce informatiche nei confronti degli utenti, evitando che gli stessi cadano nelle trappole appositamente lanciate per loro.
Il metodo colombiano del cambio del Pesos
Uno dei metodi più strutturati e che ha maggior fortuna lo troviamo nel mercato della droga tra la Colombia e gli USA.
Tra i metodi più sfruttati per riciclare il denaro in Colombia vi è il sistema inventato dai cartelli della droga. Come ha indicato l’Istituto australiano di Criminologia dopo averne studiato gli effetti per diversi anni, esso si basa parzialmente sullo sfruttamento delle potenzialità della rete e dei suoi strumenti.
La sua struttura è molto interessante: ad esempio, i trafficanti vendono negli USA della droga per un valore di 3 milioni di dollari. Questo denaro è ovviamente illecito, e soprattutto non giustificabile. Per questo si avvalgono di un sistema bancario apposito, il “Black Market Peso Exchange” dove alcuni uomini d’affari colombiani comprano i dollari sporchi e li depositano online.
Con questi dollari, gli affaristi colombiani comprano dei beni direttamente dagli USA, e una volta ricevuti li esportano in Colombia, dove vengono venduti direttamente ai cittadini, i quali pagano in pesos. I proventi di questa ultima vendita finiscono nelle mani dei trafficanti di droga, che ora possono giustificare il denaro come proveniente da una normale attività commerciale.
Se fino a pochi anni fa, l’Interpol poteva interrompere il meccanismo individuando le banche dove erano depositati i dollari americani e sequestrandoli, la possibilità di detenere soldi su fondi Paypal o Bitcoin rende difficilissimo il sequestro dei soldi, nonchè il tracciamento dei movimenti di denaro che di norma permette di risalire alle persone.
Conclusioni
È evidente che la rete offra moltissimi opportunità ai cyber criminali per riciclare denaro sporco, sia utilizzando ignari cittadini, sia sfruttando quelli che sarebbero per loro natura servizi puliti ma impossibilitati a consentire una tracciabilità.
Un approccio differente dal classico riciclaggio di denaro per modalità e quantità per riuscire a passare inosservato anche in caso di controlli e che grazie all’ampliarsi dello sfruttamento della rete ha vissuto e sta vivendo un continuo sviluppo e un perfezionamento difficile da gestire e bloccare per le autorità.
Per capire, partiamo dal valore di una moneta classica: fino ad alcuni secoli fa, questo derivava dalla quantità di metallo prezioso contenuto all’interno della moneta stessa. Mentre invece oggi non è più così. Cosa dà valore ha una moneta?
Il valore è semplicemente il potere d’acquisto, cioè la quantità o qualità di cosa posso comprare con quella moneta. E il potere d’acquisto a sua volta deriva dalla fiducia che i cittadini hanno in uno Stato che dà corso legale e stampa quella moneta.
In altre parole, la fiducia di poter utilizzare la moneta per degli scambi e dei pagamenti fa in modo che questa sia accettata da chiunque. Tanto più è forte quella fiducia, tanto più la moneta ha valore.
Cosa apprezza o deprezza una moneta? Da cosa dipende la variazione del valore?
Dipende sicuramente dal rapporto che uno Stato ha con gli altri Stati. E ovviamente dalla politica monetaria che decide di attuare: generalmente più soldi vengono stampati e meno la moneta è potente, perché ce n’è una quantità maggiore.
I bitcoin, sono considerabili una moneta vera e propria?
Attualmente no. Sono una criptovaluta, ma non una valuta. Perché non hanno ancora le caratteristiche tecniche per rientrare all’interno della definizione di moneta.
Il problema principale è la volatilità: i Bitcoin sono estremamente volatili, cioè il loro valore subisce cambiamenti frequenti anche di grande entità; e senza un valore abbastanza stabile non si può parlare di moneta.
Immaginiamo che io debba comprare un prodotto che ha un determinato prezzo: se nell’arco anche di poche ore il prezzo cambia sostanzialmente, io posso pagare di più o di meno con una rapidità destabilizzante.
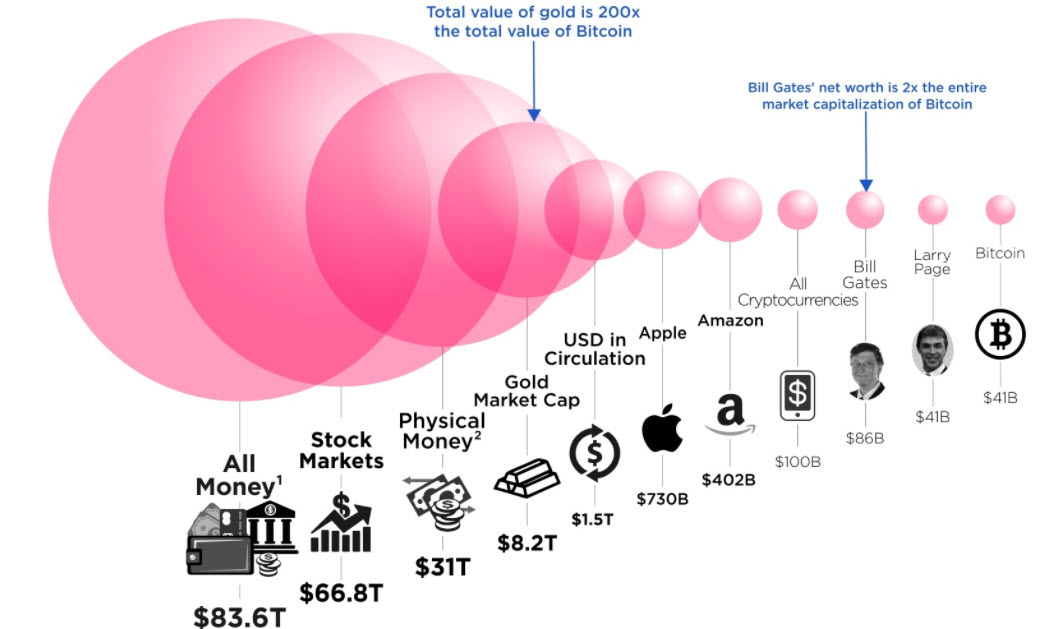
I Bitcoin hanno un valore complessivo ancora relativamente modesto, se rapportato ad altre realtà e persino ai patrimoni personali degli imprenditori top mondiali
Attenzione: con i Bitcoin ciò che cambia è il loro valore rispetto alle valute tradizionali, come il dollaro o l’Euro.
Facciamo un esempio: immaginiamo che un bene costi 8000 dollari, e un Bitcoin valga 8000 dollari. Allora il prezzo di quel bene sarà di 1 Bitcoin. Ma se nell’arco di un’ora il cambio Bitcoin/dollaro passasse da 8000 a 7000 dollari, allora il prezzo di quel bene sarà pari a 1.14 Bitcoin, che sono sempre 8000 dollari.
Essendo il valore dei beni che quotidianamente acquistiamo espressi in valuta classica, l’alta volatilità del Bitcoin comporta un’alta variazione dei prezzi, e quindi la non idoneità dei Bitcoin ad essere una valuta.
E il valore di un Bitcoin da cosa è definito attualmente?
Come tutte le cose, dal rapporto tra la domanda e offerta. Il problema è che mentre l’offerta è piuttosto rigida perché i Bitcoin possono essere minati (cioè prodotti) fino al limite massimo di 21 milioni, la domanda è invece estremamente variabile.
Questo comporta un valore incerto e molto volatile di ora in ora. Inoltre non esiste nessuna autorità centrale con il compito di stabilizzarne il valore: anche per questo il Bitcoin è diverso dalle valute classiche
Ma nel medio periodo tende ad apprezzarsi…
Sì. Evidentemente al di là della singola giornata, si può dire che il mercato stia dando abbastanza fiducia a questa criptovaluta. Viene vista, lo dicono i dati, come una scommessa.
Come la possibilità di creare un oro digitale che possa poi evolvere in una valuta reale. Questo è il motivo per cui nel medio periodo i Bitcoin tendono ad aumentare di valore.
Ma attenzione, i rischi ad investire in Bitcoin sono molteplici: oltre l’elevata volatilità, ricordiamo sempre che è un investimento senza paracadute. Non essendo fatto tramite i classici canali di investimento, e non essendo regolato, non ci sono tutele nei confronti dell’investitore.
Se ad esempio una piattaforma di acquisto Bitcoin fallisse, non ci sarebbe nessuna tutela per gli investitori, mentre sappiamo che in caso di fallimento di una banca i correntisti sono almeno in parte coperti da garanzie dello Stato. Per questo il consiglio che viene dato da molti è di investire in Bitcoin solo il capitale “available for loss”, cioè di cui si può sopportare la totale perdita.
Sono tecnicamente incorruttibili. Per questo sono considerati come “oro digitale” su cui investire
Potrebbero i Bitcoin diventare una valuta a pieno titolo e acquisire corso legale?
Al momento attuale direi di no. Lo potrebbe diventare solo se supereremo alcuni paradigmi al momento imprescindibili. Ad esempio, oggi le banche centrali possono decidere di stampare moneta per dare impulso all’economia: saremo mai pronti a perdere questa libertà e a darla in mano ad un algoritmo?
E per quanto riguarda la blockchain? questo sistema decentralizzato e distribuito dove le transazioni sono autorizzate dalla comunità (consenso distribuito)? potrebbe diventare un modello per tutti gli scambi del mondo?
Su questo esistono due teorie. La prima pensa che la blockchain esista solo in correlazione con i Bitcoin, ovvero che non possa sopravvivere senza di loro.
Altri ritengono che la blockchain potrebbe sopravvivere come sistema indipendente. Ma in questo caso ci sono dei problemi, innanzitutto i costi di gestione e il potere di calcolo necessario.
L’ipotesi più verosimile è che la blockchain possa essere utilizzata in ambienti ristretti o comunque in scenari abbastanza limitati, ma la vedo dura su scala mondiale. E’ però indubbio che l’idea di consenso distribuito che la blockchain ha portato alla ribalta è un’innovazione che avrà ripercussioni anche forti.
Secondo noi, solo la metà della gente ha capito cosa sono i bitcoin. Pochi li hanno compresi anche a livello economico, e pochissimi hanno afferrato se e come ci si può guadagnare veramente. Vi suggeriamo di ripartire da zero: affermazioni di grandi prodigi, titoloni sulla loro caduta e guide arzigogolate non fanno altro che confondere la mente dell’utente medio.
Cerchiamo, stavolta, di capire davvero di cosa si tratta e di far parte di quel fortunato gruppo di persone che li usano nel modo giusto.
Resettate la mente: capiamo davvero cosa sono i Bitcoin
Non preoccupatevi, non è difficile e nemmeno tanto lungo da comprendere.
Era il 2009, quando un signore dal nome giapponese, Satoshi Nakamoto (ma con molta probabilità un gruppo o una organizzazione incarnata in costui) pubblicò un documento dove parlava di una nuova valuta digitale, una criptomoneta, chiamata bitcoin. Si trattava di una valuta completamente virtuale, senza banche nè governi a controllarla, che poteva essere usata per scambiare beni e servizi.
Poi, nel 2010, Nakamoto sparì. E nel 2013, il fenomeno Bitcoin si impose a livello mondiale.
Andando sul pratico, per partire con i bitcoin bisogna collegarsi presso una piattaforma di scambio, un sito web, creare un profilo più o meno simile a Paypal e versare dei soldi (reali). In cambio ti vengono accreditati dei bitcoin, che puoi conservare in un portafoglio virtuale (wallet) che risiede online oppure fisicamente sul tuo PC o in una chiavetta USB. Da quel momento puoi comprare beni su internet pagando in bitcoin.
Ok, direte voi, è una moneta digitale alla fine. Una variante virtuale dei soldi… eh no. È un cambiamento di sistema.
Mai più banche e Governi cattivi: un sistema diverso
I bitcoin si propongono come alternativi ad altri due sistemi: quello centralizzato e quello decentralizzato.
Nel primo caso esiste un Governo, un ente centrale, che stampa moneta, la distribuisce ai singoli e assicura il valore di quella moneta. Ad esempio, fino alla seconda guerra mondiale il valore della moneta corrispondeva alle riserve auree conservate presso lo Stato. Tu usi il denaro perché ti fidi del valore che gli attribuisce il tuo paese e che gli danno gli altri con cui commerci.
Il secondo sistema è quello decentralizzato. Ovvero, non c’è più un solo ente superiore, ma più enti “grossi” che distribuiscono moneta e valore ai singoli.
La terza variante, su cui vive bitcoin, è il sistema decentralizzato e distribuito. Qui non esiste alcun ente superiore, regolatore o legislatore. Tutti sono uguali, e uno vale uno.
Ogni transazione viene vista e approvata dalla comunità. Tutto pubblico e tutto tracciato, raccolto in una serie di “blocchi” di scambi. E’ la Blockchain, il nuovo sistema decentralizzato e distribuito
In questo caso immaginiamo che io voglia fare una transazione con qualcuno. Raccolgo i dati necessari e le informazioni utili, e poi chiedo a tutti gli altri che scambiano nel mondo se la mia transazione è corretta e può essere autorizzata. Se tutto il gruppo, se tutta la comunità, mi dà l’ok, la transazione avviene.
Un gruppo di transazioni in un determinato periodo di tempo viene chiamato “Blocco” o “Block“. E i blocchi uno dopo l’altro, formano una “catena di blocchi”, ovvero una “Blockchain“.
Questa è la rivoluzione, e anche quello che ha attratto l’attenzione mondiale: tutti sono pari, non ci sono le banche o i Governi cattivi a comandare, non esistono commissioni da pagare o tasse.
Esistono gli scambi tra persone, semplicemente. Inoltre le transazioni sono segnate e tracciabili per sempre, ma gli autori della transazione, i cosiddetti “nodi”, sono nell’anonimato più assoluto.
Certo, si può tentare di tracciarli, ma bastano dei “Mixer” per mescolare i dati, e chi ha fatto lo scambio non lo trovi mai più.
Una nuova corsa all’oro. Minare i Bitcoin
Per capire più a fondo il fenomeno dei Bitcoin, bisogna comprende anche il concetto di Mining. Si tratta sostanzialmente di prendere un blocco di transazioni e avviare, tramite dei computer, una serie di calcoli matematici.
Questi calcoli, una volta terminato il processo, arrivano a definire una sequenza numerica, detta Hash, che identifica il blocco. Ebbene, la meraviglia sta nel fatto che quando riesci ad ottenere l’Hash di un blocco, questo si converte in 12.5 Bitcoin.
Così come una volta ci si metteva nei fiumi a cercare con il passino fino a che trovavi una pepita d’oro, adesso ci si mette a fare calcoli con i computer per scovare un numero Hash che diventa denaro.
Nakamoto, sin dall’alba dei tempi, impose un limite massimo mondiale di 21 milioni di Bitcoin minabili, e al momento attuale ne sono stati minati 12 milioni.
In teoria chiunque può minare bitcoin, e su Amazon si possono trovare computer per provare a minare delle valute minori, ma una attività di questo tipo è praticamente appannaggio di progetti di stampo industriale.
Ed è accaduto anche che nel 2017 si sia verificata una specie di lite fra i “minatori”. Alcuni volevano eseguire i calcoli su blocchi di 1MB, come è sempre stato, mentre altri volevano poter minare blocchi più grandi, di 8MB. Il risultato è stato un “Fork”, cioè una divaricazione nel mining.
Nel frattempo sono nate anche alcune valute indipendenti come Ethereume Bitcoin Cash.
I primi a capire le potenzialità dei bitcoin: i ladri
I primissimi a comprendere la funzione e le potenzialità dei bitcoin sono stati i criminali di tutto il mondo.
Un risparmiatore rovinato dal furto alla piattaforma MtGox, nel 2014. Tra hacker e fallimenti, evaporarono bitcoin per l’equivalente di 345 mln di euro
Per prima cosa sono stati attaccati i portafogli virtuali online che conservavano i bitcoin dei loro clienti. Famoso fu il caso di Mt Gox, che si vide sottrarre 750mila bitcoin. Più recentemente NiceHash ne ha persi altri 4.700. Ma anche i virus che rubano i wallet conservati in locale sul PC hanno fatto danni.
Ancora peggio. Esistono da diversi anni dei virus chiamati Ransomware, che arrivano su un pc, criptano il contenuto rendendolo illeggibile e chiedono un riscatto in denaro per consegnare la chiave necessaria a decifrare e riottenere i propri dati.
Questi malware avevano però un problema: una transazione verso una banca può essere tracciata. E i bitcoin, tracciabili ma non associati ad un nominativo esplicito, hanno risolto il problema.
Le vittime erano costrette a convertire denaro reale in bitcoin, e pagare i pirati informatici in maniera anonima.
Ma anche il commercio illegale ne ha approfittato: Silk Road è stato un gigantesco portale di e-commerce di prodotti illegali, dalle armi, alla droga, ai DVD o materiale d’autore, che si faceva pagare in bitcoin.
I clienti, sicuri di non poter essere rintracciati, hanno usato allegramente i bitcoin in barba alle autorità.
L’aspetto economico: i bitcoin sono volatili
A questo punto possiamo finalmente dire di aver compreso i bitcoin sotto l’aspetto tecnico. Ma dal punto di vista economico devono essere chiari altri due elementi.
Il primo è la estrema volatilità. Proprio perché fa parte di un sistema distribuito dove non ci sono autorità, il valore di un bitcoin non è definibile in maniera precisa. Questo dipende piuttosto dall’andamento, dalla fiducia o dall'”umore” della comunità che li usa. Un bitcoin può valere €8000 euro al mattino, scendere a €7000 la sera e tornare a €9000 il giorno dopo. Gli sbalzi di valore sono continui e molto forti.
Quello che possiamo dire con sicurezza, è che nel medio-lungo periodo, tende ad apprezzarsi in maniera piuttosto stabile.
I bitcoin non sono (ancora) una moneta
La seconda cosa da comprendere è che il bitcoin, non è una “moneta”, perché non ha le caratteristiche che storicamente la definiscono.
Innanzitutto una moneta deve essere una unità di conto. Cioè devo poter dire con ragionevole sicurezza che con 1 Euro, centesimo più o centesimo meno, posso comprare una zucchina. La volatilità dei bitcoin impedisce però agli stessi di essere usati come unità di conto. Il che gli impedisce di essere considerati moneta.
In secondo luogo, una moneta deve poter essere usata per fare scambi. Io consegno due etti di crudo e ricevo in cambio della moneta perché ho fiducia di poterla riutilizzare a mia volta per altri scambi. Una volta la sicurezza derivava dal fatto che il valore della moneta era nella moneta stessa, ad esempio una quantità di oro, incorruttibile. Adesso ci fidiamo più che altro del valore dato dallo Stato a quella moneta.
In questo caso i bitcoin funzionano: sono effettivamente incorruttibili, tanto che vengono definiti “oro digitale” e possono essere usati per degli scambi perché esistono altre persone che credono di poterli usare a loro volta.
La terza caratteristica di una moneta è però la possibilità di usarla come pagamento, e qui non ci siamo. Si, è vero, abbiamo appena detto che possono essere usati per fare scambi, ma i pagamenti sono un’altra cosa. Ad esempio, a fronte di un debito, io faccio un pagamento ad un creditore tramite dollari od euro che, avendo corso legale, è obbligato ad accettare. Questo mi rende libero, ovvero svincolato dal quel debito.
I bitcoin non hanno ancora le caratteristiche per essere definiti una moneta. Non vanno trattati come i soldi normali.
Nel caso dei Bitcoin, non avendo un corso legale, il creditore può rifiutarsi di accettarli come mezzi di pagamento, e dunque non sono utilizzabili con la stessa stabilità delle monete classiche.
Infine, la moneta deve avere un valore relativamente stabile. E di nuovo, i bitcoin non ce l’hanno: il fatto accade perché l’offerta di Bitcoin è piuttosto fissa, non può aumentare rapidamente, mentre la domanda può variare in un attimo. Da qui le intense fluttuazioni.
Per cui, dobbiamo sapere che i bitcoin sono una valuta di scambio, ma non hanno corso legale e non vanno trattati come i soldi normali. In altre parole, non hanno ancora le caratteristiche per definirsi “moneta” a pieno titolo.
Bitcoin. Capiamo finalmente chi ci guadagna e chi ci perde
Abbiamo superato indenni la parte didattica, ma ora è tempo di capire meglio se il fenomeno Bitcoin è una colossale bolla speculativa, paragonata da alcuni a quella del 1600 sui tulipani in Olanda, o se siamo di fronte ad una rivoluzione da capire e da abbracciare.
Partiamo da una domanda semplice: con questi bitcoin, finora, chi ha guadagnato veramente? Per rispondere abbiamo chiesto al Prof. Ferdinando Ametrano, che insegna Bitcoin and Blockchain Technologies alla Bicocca di Milano, ed ha la particolarità di non avere colleghi, perché è il primo in Europa ad avere un insegnamento sull’argomento.
“Ok facciamo una classifica – dice con voce squillante al telefono – i primi in assoluto sono i “cassettisti”, quelli che hanno comprato bitcoin un anno fa o prima e li hanno detenuti senza spenderli né scambiarli. Hanno guadagnato più di tutti, perché hanno trattato i bitcoin come “oro digitale”, bene rifugio, aspettando che si apprezzassero.
Al secondo posto ci sono le piattaforme di scambio, quelle che intermediano la compravendita di bitcoin raccogliendo commissioni. Al terzo posto… i furfanti: quelli che hanno messo in piedi un circo di piccole e grandi frodi e che spesso manipolano le contrattazioni con la complicità di borse di scambio poco affidabili”. E chi ci ha perso? “Gli utenti medi che, senza comprendere la natura di bitcoin, li hanno comprati e poi rivenduti, facendo trading magari anche su frequenza giornaliera: hanno perso alla grande su un mercato significativamente manipolato“.
I cassettisti: sono quelli che con i bitcoin possono dire di aver qualcosa in mano. Chi ha fatto speculazioni scambiano in giornata ha perso… alla grande
Ok ma adesso i Governi stanno iniziando a vietare i bitcoin. Per cui il sogno è già finito? “Assolutamente no – risponde Ametrano – perché i Governi non possono tecnicamente bloccare Bitcoin: dovrebbero fermare tutti i nodi della rete, più di 10000 sparsi in tutto il mondo.
Quello che possono fare è tentare di strozzare o proibire bitcoin, magari nascondendosi dietro l’esigenza di regolamentarlo: nel 1933 gli USA vietarono il possesso di oro. In ogni caso il proibizionismo non ha mai funzionato, il valore del bene proibito semplicemente aumenta ed il mercato non si ferma”.
Ma forse il problema potrebbero essere i privati? Perché quando abbiamo detto che nella blockchain ognuno chiede agli altri se può eseguire la transazione, è evidente che la richiesta, il controllo e l’autorizzazione sono automatici, eseguiti da computer.
Ma se la Blockchain diventasse negli anni sempre più grossa, con sempre più richieste da gestire, potrebbero essere necessarie delle web farm di elaborazione dati gentilmente “offerte” da grandi aziende.
Ferdinano Maria Ametrano, unico in Europa ad avere un insegnamento su Bitcoin e Blockchain Technologies: “I bitcoin vanno visti come oro digitale. Se reggono alla prova del tempo potrebbero avere un notevole impatto sull’economia mondiale”
E queste grandi aziende, contribuendo in maniera sostanziale al funzionamento e stabilità della blockchain ne potrebbero parimenti influenzare il comportamento? “No, – taglia corto Ametrano – bastano 150GB di spazio su un PC per diventare un nodo della rete con una copia integrale della blockchain.
Operare un nodo della rete non è particolarmente gravoso, non servono grandi aziende. Ed è proprio il fatto che la blockchain è distribuita che ha garantito il funzionamento ininterrotto di bitcoin”.
Il mining di Bitcoin è in mano a pochi produttori. “Ma non è un problema – spiega Ametrano – in ogni caso potrebbero intervenire altre aziende”
“Se vogliamo parlare di oligopolio – prosegue Ametrano – c’è nei fatti per quello che riguarda i nodi che svolgono l’attività computazionalmente intensa del mining. Attualmente circa il 70% dell’hardware usato per minare bitcoin è prodotto da Bitmainche lo vende a tre/quattro aziende.
Ma stanno arrivando anche altri produttori, compreso un gigante come Samsung. In ogni caso il mining, se sufficientemente decentralizzato e distribuito, non ha la possibilità di influenzare bitcoin o di manipolare la blockchain.”
Ma se un Governo andasse a dire a chi ha il monopolio del mining che se non vuole avere problemi con il fisco dovrebbe ridurre o sospendere le attività? Oppure se domani un miner determinante minacciasse di interrompere i lavori se non in cambio di una percentuale sulle transazioni?
“Subentrerebbero altri miner, in altre aree geografiche – chiosa Ametrano – altri attori motivati da interessi economici, culturali e politici a sostenere la rete bitcoin”
Perfetto. E infine la domanda delle domande: se fossi un utente medio, che vuole sfruttare i bitcoin stando dalla parte di chi ci ha guadagnato e non del “fesso che ci ha perso” che dovrei fare?
“Per prima cosa – spiega con sicurezza Ametrano – bisogna studiare per comprendere che bitcoin può essere una ragionevole diversificazione dei propri investimenti. Significa aggiornarsi tecnologicamente e familiarizzare con un significativo cambiamento di paradigma culturale, che se regge alla prova del tempo potrebbe avere un notevole impatto sull’economia mondiale.
Quali sono le piattaforme di scambio bitcoin più affidabili? Chicago: Gemini, GDax, ItBit, Kraken, Bitstamp. E l’italiana TheRockTrading: nel mondo è la più vecchia borsa bitcoin tutt’ora funzionante
In secondo luogo si può investire in bitcoin quella parte di capitale di cui si possa sopportare senza troppi rimpianti l’eventuale perdita. Siamo di fronte a una svolta storica: se davvero bitcoin rappresenta l’oro digitale, allora il suo potenziale è persino sottovalutato e dovrà apprezzarsi decine di volte; se invece dovessero emergere elementi critici che oggi sfuggono alle analisi, allora il suo valore è destinato ad azzerarsi.
Terza regola, affidarsi per la compravendita a borse di scambio affidabili, ma evitare assolutamente di custodire i propri bitcoin presso le borse, che potrebbero fallire o essere violate: bisogna gestirli attraverso un proprio software wallet, a cui altri non possano accedere: bitcoin nasce per non doversi fidare di intermediari”.
Quali borse sono affidabili? “Quelle utilizzate come mercati di riferimento per il prezzo di riferimento dei futures quotati a Chicago: Gemini, GDax, ItBit, Kraken, Bitstamp. A questi aggiungerei l’italiana TheRockTrading: nel mondo è la più vecchia borsa bitcoin tutt’ora funzionante; non si sono fatti bucare da hacker, non sono scappati con i soldi dei clienti: credenziali minimali, ma nel new wild west di bitcoin sono le migliori che si possano esibire”.
Ultimo ma non ultimo: “Bitcoin è un bene rifugio, oro digitale. Meglio evitare il trading speculativo, acquistarli e rivenderli dopo pochi giorni: va considerato come un investimento di lungo termine, meglio fare i cassettisti. È solo così che, se l’esperimento bitcoin avrà successo, potranno realizzarsi guadagni significativi”.
Google e Facebook non hanno solamente miliardi di utenti a disposizione, ultra controllati e monitorati, ma ci seguono anche quando non li usiamo. Dal momento che la stragrande maggioranza dei siti internet include dei loro codici nelle pagine web, diventando un ponte per il controllo pressochè totale della popolazione mondiale.
E’ l’analisi lanciata da Gabriel Weinberg, CEO e fondatore di DuckDuckGo, un motore di ricerca che si distingue per il completo anonimato dei suoi utenti.
Privacy. Così Google e Facebook tengono in pugno il web
Google, azienda statunitense fondata nel 1998, detiene oggi il primato dei motori di ricerca. Coordina altre attività leader del settore informatico e tecnologico, grazie alle quali accede con facilità alle informazioni degli utenti
Secondo il progetto “Web Transparency & Accountability“ di Princeton, il 76% dei codici di tracciamento nascosti all’interno dei siti web appartiene a Google e il 24% a Facebook. Sono seguiti da Twitter al 12%. È certo quindi che Google o Facebook ci monitorino su molti siti che visitiamo, oltre a rintracciarci quando utilizziamo i loro prodotti.
Di conseguenza, queste due società hanno accumulato enormi profili di dati su ogni persona, che possono includere interessi, acquisti, ricerche, cronologie di navigazione, geo-localizzazione e molto altro ancora. Una enorme mole di informazioni che mettono a disposizione di gruppi di sponsor per pubblicità mirate e invasive che ci seguono su Internet.
Proprio per la loro posizione all’interno di una vasta gamma di servizi del web, Google e Facebook possono raccogliere informazioni personali che si combinano insieme in enormi profili digitali al fine di offrire un iper-targettizzazione migliore rispetto alla concorrenza.
Secondo eMarketer, gestiscono ora il 63% di tutta la pubblicità digitale del mondo, e hanno rappresentato nel 2017, il 74% della crescita in questo mercato. Insieme formano un denso duopolio della pubblicità digitale, che non presenta segni di cedimento e che blocca la strada a qualsiasi competitor.
Facebook, social network nato nel 2004 collabora ora con altre app di condivisione e agenzie pubblicitarie, grazie alle quali reindirizza i propri utenti verso ricerche personalizzate
Ma il controllo di questi due giganti del web non si limita ai dati e alla pubblicità, ma può distorcere la nostra percezione mentre navighiamo sul web.
Google e Facebook usano i dati raccolti come input per elaborare algoritmi di intelligenza artificiale sempre più sofisticati. Questi ci inseriscono all’interno di quella che viene definita “bolla di filtraggio”. Una serie di impostazioni, risultati di ricerca, preferenze di navigazione, che creano un “universo digitale” personalizzato per noi.
Certamente bello, ma allo stesso tempo pericoloso: questo sistema distorce la realtà, mostrandoci o nascondendoci informazioni a nostra completa insaputa.
La ricetta di Weinberg: cosa dovrebbero fare i Governi
Con questo obiettivo di trarre sempre più profitto da informazioni personali, Google e Facebook hanno mostrato scarso rispetto per tutte le conseguenze negative dei loro algoritmi.
Su pressione dei Governi e delle normative, le due multinazionali hanno spesso attuato delle politiche di autoregolamentazione, ma in realtà, secondo l’analisi di Weinberg, si tratta di illusioni.
Qualsiasi restrizione a lungo termine sulla privacy dei dati forniti a Google e Facebook si oppone fondamentalmente ai loro modelli business di pubblicità iper-mirata, basata su una sorveglianza personale sempre più intrusiva.
Sfortunatamente, ben poco è stato fatto da parte delle autorità mondiali. I parlamenti, secondo la soluzione prospettata da Weinberg, devono studiare soluzioni efficaci per frenare questo monopolio di dati. Innanzitutto, è necessario richiedere maggiore trasparenza degli algoritmi e sulla privacy, in modo che le persone possano veramente comprendere il modo in cui le loro informazioni personali vengono raccolte, elaborate e utilizzate da tali società. Solo allora sarà possibile il consenso informato.
C’è anche bisogno di proporre nuove leggi sul possesso inalienabile dei propri dati. Infine, si dovrebbe limitare il modo in cui i dati possono essere riutilizzati, inclusi strumenti più aggressivi per bloccare le acquisizioni dei dati, che consolidano la potenza dei gruppi sopra citati e che aprirà la strada a una maggiore concorrenza nella pubblicità digitale.
Agli utenti viene offerta la possibilità di definire restrizioni sulla propria privacy che però non vengono totalmente rispettate
Finché non vedremo cambiamenti significativi da parte delle istituzioni, i consumatori dovrebbero esprimere il proprio dissenso. DuckDuckGo ha scoperto che circa un quarto degli americani stanno già intraprendendo azioni efficaci per riappropriarsi della propria privacy.
Aiuti giungono anche da componenti aggiuntivi del browser che riescono a bloccare i tracker nascosti di Google e Facebook, oltre a fornire alternative private ai loro servizi principali.
La completa perdita di privacy nell’era di Internet non è inevitabile. Attraverso una regolamentazione ponderata e una maggiore scelta del consumatore, possiamo scegliere un percorso più funzionale. Dovremmo guardare al 2018 come un punto di svolta nella privacy dei dati, nel quale ribellarsi alle implicazioni inaccettabili di due società che controllano così tanto il nostro futuro digitale.
L’HTML 5, il nuovo linguaggio erede di Flash Player è davvero così completamente al sicuro? O esistono delle vulnerabilità di sicurezza che lo rendono un prodotto non del tutto inattaccabile?
Adobe Flash Player, lo storico strumento per la visualizzazione di elementi multimediali su internet, che ha dominato gli anni ’90 e i primi anni 2000, cesserà di esistere nel 2020 ed la soluzione destinata a prendere il suo posto è senza dubbio l’HTML 5, ormai da tempo considerato da sviluppatori ed utenti il degno successore di questo programma.
Tecnicamente l’HTML5 possiede delle caratteristiche che rendono più facile per i programmatori creare dei siti web in grado di caricare e far funzionare video in differenti formati: il contenuto che è possibile ottenere non avrà problemi infatti ad essere riprodotto su computer desktop, tablet, smartphone, televisori e piattaforme di gaming.
E non si può fare a meno di ricordare che anche YouTube, il noto aggregatore di video, è già passato da tempo all’HTML5 abbandonando Adobe Flash Player e dando modo di adattare e far cambiare automaticamente la risoluzione video in base alla connessione di rete dell’utente finale per ottenere una migliore performance.
Un altro esempio? E’ grazie a questa tecnologia che i gamer della Xbox One possono eseguire delle live stream delle proprie partite.
Per ottenere un prodotto completo soprattutto in materia di streaming e video conferenza l’HTML 5 deve essere integrato con Javascript e CSS3.
Attenzione però: questo non significa che tale struttura possa rimpiazzare interamente il prodotto di Adobe: l’HTML5 non è infatti in grado, ad esempio, di interagire con una webcam e l’audio registrato da un microfono e da solo non può essere usato per creare animazioni o video interattivi. In questi casi vi è bisogno di integrare JavaScript o CSS3 per raggiungere il risultato sperato.
Ma sul fronte della sicurezza? L’HTML5 è più sicuro da usare in alternativa a Flash? Sicuramente sì. Ma vi sono delle falle alle quali fare attenzione per prevenire i problemi.
HTML 5. Prima vulnerabilità: il codice sorgente è troppo leggibile e attaccabile
Una delle prime vulnerabilità collegate all’HTML5 risiede nel codice sorgente facilmente leggibile da qualsiasi browser in tutte le pagine che non hanno una connessione criptata. Qualsiasi persona capace di visionare l’header, le sezioni, gli articoli ed i tag video potrebbe essere in grado di raggiungere i file video. Un semplice esempio di codice non criptato facilmente sfruttabile:
<video width=”320″ height=”240″ controls>
<source src=”movie.mp4″ type=”video/mp4″>
<source src=”movie.ogg” type=”video/ogg”>
<source src=”movie.webm” type=”video/webm”>
</video>
Come è possibile notare, i file video sono elencati in bella vista con tutto ciò che necessita ai browser per visualizzarli, sia sui dispositivi fissi che mobili. E sebbene alcuni formati non possano contare su supporti diretti da parte di alcuni browser, nella maggior parte dei casi basta una semplice connessione ad internet per dare modo ai malintenzionati di agire sui brani video del sito.
Tramite software di terze parti in grado di convertire i file AVI in MP4 o se le clip video sono caricate tutte in questo formato, facilmente leggibile da ogni browser, si possono eseguire danni concreti.
Un hacker o chiunque voglia sferrare un attacco, con un codice HTLM5 non criptato, non avrà problemi a trovare i video, farne una copia, modificarne i frame inserendo codice pericoloso e da lì tentare di entrare nell’amministrazione del sito web.
Il codice sorgente, se troppo visibile, può essere pesantemente sfruttato dai pirati informatici
HTML 5. Secondo bug: non ci sono strumenti di sicurezza per i tutti i browser
Un’altra vulnerabilità di questo codice, da non sottovalutare, è che manca di strumenti e sistemi di sicurezza sufficientemente solidi. Il problema fondamentale è la mancanza di un sistema di autenticazione FIDO (Fast Identity Online) che rende la maggior parte dei browser esposti all’esecuzione di codice dannoso, nascosto tra le pieghe dei tag HTML 5.
Solo Firefox 54 e Xbox One al momento hanno parzialmente implementato questo sistema ma il WWWC (World Wide Web Consortium) non ha ancora elaborato delle regole di sicurezza comuni per tutti i browser, nel momento in cui visualizzano una pagina in HTML 5.
Grazie ad HTML5Test, un’applicazione web molto popolare che calcola quanto funzionino bene i diversi browser, si può verificare come i più sicuri per visualizzare l’HTML 5 siano Opera 45 ( punteggio 518 su 555) e Edge 16. Ma si tratta di strumenti ancora incompleti e che non danno sufficiente protezione.
HTML 5, la terza falla: è facilissimo inserire codice malevolo
L’ultima importante falla dell’HTML5 consiste nel fatto che è molto facile inserire del codice malevolo dall’esterno. L’HTML 5 in realtà è molto ricco di codici per far funzionare degli elementi: ci sono quelli per la comunicazione come le chat integrate sui siti web, quelli che si occupano delle integrazione con i social network, gli strumenti per la geolocalizzazione, o per gestire le applicazioni offline.
Qualsiasi hacker o programmatore può attaccare un sito tramite vulnerabilità dell’HTML 5 e inserire del codice malevolo creando danni: ad esempio può attivare un loop infinito di un video o un elemento interattivo, bloccando un sito web.
Problema simile nel caso in cui si attacchi un “sandboxed frame”: in questo caso si può ottenere il totale blocco del video riprodotto nel sito. Non solo: anche i messaggi scambiati fra il sito web e i navigatori, come una chat per un supporto tecnico, possono essere alterati o spediti agli interlocutori sbagliati. E ancora: i web socket possono essere sottoposti ad attacchi DoS e di conseguenza i server che ospitano il sito potrebbero dover gestire una serie di richieste false in grado di rallentare il portale.
Cosa indica questo? Che per quanto il formato HTML5 sia avanzato ed in grado di gestire al meglio la creazione e gestione di file video “intelligenti”, alcune sue falle nella sicurezza potrebbero mettere a rischio il sito web, a volte in modo maggiore rispetto a ciò che accadrebbe utilizzando Flash.
Per l’HTML 5 il rischio più elevato è quello di esecuzione da parte del browser di codice malevolo inserito nelle pagine web
HTML 5. Come mettere in sicurezza il codice e i video
Come già anticipato, le falle di sicurezza nell’HTML5 ci sono, ma questo non significa che non si possa fare niente per ovviare alla loro presenza. Ecco alcune delle azioni che si possono intraprendere:
Criptare il codice sorgente HTML5 e rendere impossibile per le persone intenzionate ad attaccare il sito web l’utilizzo di strumenti come Encrypt HTML Pro
Installare un’utility in grado di filtrare il codice per rimuoverne le parti modificate e pericolose: il migliore in tal senso è HTML Purifier
mantenere sempre aggiornati i router wireless e i dispositivi Bluetooth
ridurre i permessi relativi ai codici non sicuri
prevenire la stampa o la copia del codice sorgente
cambiare le password di amministratore date di default
trovare gli input provenienti da fonti non attendibili e non consentirgli di girare
utilizzare HTML5Testper testare il supporto sicurezza per i propri browser
far girare HTML5 con HTTPS
Per aumentare la sicurezza dell’HTML5 utilizzato nel proprio sito è poi raccomandato utilizzare i seguenti HTTP headers:
X-Frame-Options
X-XSS Protection
Strict Transport Security
Content Security Policy
Origin.
HTML5: l’importanza degli aggiornamenti
Le falle dell’HTML5 insegna una lezione inconfutabile: per godere di questo linguaggio, tutti gli strumenti collegati dovranno essere sempre aggiornati. Solo in questo modo si potrà lavorare in modo sicuro.
La futura dipartita di Adobe Flash Player rappresenterà un problema? No. Il passaggio ad HTML 5 è un passo in avanti gigantesco, specie per la sicurezza, e le enormi possibilità dell’HTML5 si vedono già con grande soddisfazione. Ma è importante ricordare che ogni persona o azienda che vorrà lavorare con questo nuovo linguaggio dovrà conoscerne gli inevitabili difetti, senza pensare di lavorare con uno strumento immune alle vulnerabilità.
Le applicazioni per il fitness spopolano nel mondo, permettendo di tenere sotto controllo peso, allenamenti e forma fisica. Ma quando i dati raccolti per anni vengono mostrati su una mappa e da qui si scoprono i movimenti dei soldati USA, le basi segrete e le linee di rifornimento, qualcosa non torna. E’ il caso Strava, che ha costretto i massimi vertici militari americani e internazionali a prendere provvedimenti.
Strava.com, definita “Social Network degli atleti”, è una società di rilevazione con sede a San Francisco che vanta circa 27 milioni di utenti in tutto il mondo.Questi accedono all’app tramite dispositivi per il fitness (es. Fitbit e Jawbone) oppure iscrivendosi direttamente al sito.
I dati vengono raccolti tramite GPS in forma anonima e distribuiti su mappe termo-luminose, rendendo evidenti i percorsi più seguiti. Il primo aggiornamento globale di Strava risale a novembre2017.
Sulla base dei dati, circa un miliardo, dal 2015 al 2017, la società ha caricato per la prima volta una mappa che mostra l’attività fisica degli utenti in tutto il mondo. Ovviamente, le aree urbane sono quelle che rappresentano un agglomerato più denso.
Strava è un’azienda leader nel monitoraggio dell’attività atletica. Nata nel 2009 a San Francisco, è ora un vero e proprio social network per sportivi
Le app per il fitness hanno svelato i tragitti degli utenti. Anche dei militari USA
Sono però alquanto strani i luoghi desertici, che dovrebbero essere isolati, ma che presentano invece zone molto fitte. Il motivo di tale stranezza è stato scoperto dall’australiano NathanRuser.
Studente di sicurezza internazionale e Medio Oriente, ha deciso di analizzare la questione sul conflitto in Siria postando su Twitter una frase provocatoria che ha scosso l’opinione pubblica. La sua osservazione è stata subito approfondita da esperti in materia, come l’analista tedesco in materia di sicurezza internazionale, Tobias Schneider.
Tale rivelazione è incentrata sul fatto che alcune di quelle rotte sembrano tracciare posizioni militari statunitensi segrete all’estero. La mappa permette infatti di identificare per nome le basi dell’esercito militare e i suoi percorsi in zone del Medio Oriente.
Il WashingtonPost ha quindi postato online la “Global heatmap” di Strava che rivela, tra gli altri, gli avamposti dell’esercito americano, tra le più pericolose e segrete location al mondo, oltre ai tracciati dei convogli militari e le ronde di perlustrazione. È facile così individuare non solo la posizione, bensì i nomi delle basi e delle città nelle quali sono ubicati, possibilità che il sito offre agli utenti ai fini della condivisione della propria posizione sui vari social network.
In questo modo è stato scoperto, ad esempio, il tracciato più utilizzato in Iraq, soprannominato dai suoi utenti “Base Perimeter”. Un altro, situato all’esterno della grande base americana in Kandahar, Afghanistan, viene chiamato “Sniper Alley.”
La scoperta delle basi e degli spostamenti militari
La notizia ha portato esperti militari, soldati e gran parte di internet a perlustrare la mappa, alla ricerca di prove dell’attività, chiedendosi se il rilascio di tali informazioni sensibili sulla posizione possano in qualche modo fornire una supervisione della sicurezza militare, oltre che comprometterla.
Le “Global heat map” rivelano la posizione e gli spostamenti dei militari in Medio Oriente
L’esercito militare ha dovuto quindi rispondere all’inchiesta circa le problematiche riguardanti le nuovetecnologie. Il maggiore AudriciaHarris ha dichiarato tuttavia che il personale del Dipartimento della Difesa sa già come limitare i profili personali su internet e sulle misure di sicurezza interna ed estera.
Nonostante ciò, i dati recenti mettono in risalto la necessità di assumere maggior consapevolezzadella situazione. Il Dipartimento della Difesa sta ora cercando di determinare se sia necessaria una formazione in materia per i propri soldati.
Come evidenzia l’ufficio stampa del Commando Centrale in Kuwait, portavoce della coalizione contro lo Stato Islamico, il rapido sviluppo di nuove tecnologie di informazione migliora le nostre vite ma pone dure sfide a chiunque operi a livello di sicurezza e protezione. Costringe a ridefinire le proprie politiche e procedure.
L’accesso pubblico a tali dati potrebbe rappresentare una vera e propria catastrofe come rivela NathanielRaymond, presidente del Programma di sicurezza umana e tecnologia di Harvard. Analizzando l’impatto dei dati tecnologici sull’uomo, considera da sempre la pericolosità dei dispositivi GPS e delle compagnie che li monitorano.
Per esempio, sempre TobiasSchneider, ha identificato il nome di ben 573persone che ogni mattina fanno jogging intorno al quartier generale dell’intelligencebritannica, il che molto probabilmente li identifica come agenti di questa istituzione.
Il problema non riguarda solo la possibilità di individuare facilmente le basi militari su una mappa. Molto spesso la loro posizione geografica è già nota, come anche gli spostamenti dei militari all’esterno della base.
I soldati statunitensi utilizzano applicazioni con GPS, fornite proprio dal Pentagono, con lo scopo di indurre il proprio personale a muoversi di più e a fare esercizio fisico. In questo modo è però possibile utilizzare i dati per programmare imboscate o ricostruire le dinamiche di movimento all’interno della base o in aree dove molto probabilmente ne verrà allestita una nuova.
Inoltre le zone a più alta concentrazione potrebbero essere quelle di ristoro o i dormitori, il che permette agli avversari di identificare un obiettivo più specifico. Diventa facile anche seguire le aree di pattugliamento, il che compromette il lavoro di segretezza sviluppato dagli Stati Uniti, i quali tendono a non rivelare aree specifiche del loro operato.
Le missioni segrete in Afghanistan, Iraq e Siria rischiano di essere compromesse, mettendo in pericolo i soldati stessi
Nessuna legge per la gestione dei dati. Così è nato il caso Strava
Il problema principale è che non è stato istituito un codice regolatorio per compagnie come Strava che collezionano informazioni degli utenti. Il loro rispetto per i dati sensibili non è ancora stato definito, il che li esclude da determinate responsabilità.
Strava risponde alle accuse dimostrando che, tramite il proprio blog, riesce a indirizzare gli utenti al fine di gestire la loro privacy sulla piattaforma. Strava sostiene che la heat map globale rappresenta una visione aggregata e anonima di oltre un miliardo di attività caricate sulla piattaforma.
Esclude pertanto zoneprivate o delimitate dai parametri impostati a priori dall’utente. Si impegna quindi ad aiutare le persone a comprendere meglio le proprie impostazioni per dare loro il controllo su ciò che condividono. Il loro intento non è quindi quello di divulgare tattiche, tecniche o procedure.
Poiché il governo militare vuole avviare procedure di sensibilizzazione circa l’utilizzoresponsabile dei dispositivi di localizzazione e Strava prende la sicurezza dei propri utenti seriamente, c’è l’intenzione di collaborare al fine di salvaguardare le aree sensibili dell’attività in questione.
L’azienda ha la convinzione che la trasmissione dei dati sensibili sia naturalmente opzionale, e che debba spettare alle decisioni personali di ogni utente se condividere o meno i propri spostamenti. È vero però che l’utente è ben predisposto ad acconsentire alla condivisione poiché questa permette di accedere ad altri servizi e, funzionando in maniera simile ad altri social network, permette di confrontare i propri risultati con quelli di altre persone che utilizzano l’applicazione.
Quante informazioni, password, accessi e conoscenze ha un collaboratore fidato dopo anni di lavoro insieme? E che danni potrebbe provocare alla vostra azienda se per un licenziamento o l’incrinarsi dei rapporti, decidesse di usare tutto quello che sa contro la vostra azienda per vendetta?
Per quanto ci si possa illudere di avere tutto sotto controllo e di avere a che fare con gente onesta non è possibile non considerare la variabile della vendetta, che in un contesto lavorativo può essere espressa in tanti modi. Il più pericoloso è senza dubbio quello della vulnerabilità di sistema e di sfruttamento delle falle nello stesso, facilmente utilizzabili da coloro che lo conoscono e che in passato ne hanno avuto accesso.
Per i dirigenti che si possono trovare in questa situazione, esiste una strategia di risposta elaborata dall’esperto statunitense William Evanina, che ha collaborato con l’FBI.
Approcciare questo tema con la giusta serietà, non concentrando in un solo reparto le responsabilità della sicurezza ma creando un network di risorse in grado di collaborare per far sì che nulla metta in pericolo l’azienda ed il suo lavoro.
La migliore difesa consiste nel preparare una squadra in grado di fronteggiare i problemi nel più breve tempo possibile.
Costruisci una squadra per elaborare la strategia migliore
La sicurezza informatica è tra le basi del corretto funzionamento di qualsiasi società, soprattutto in tempi in cui anche una stampante in linea, se dotata di una porta di accesso alla rete, può trasformarsi in una falla da eliminare. Per prima cosa, sono così tante le possibili minacce al sistema aziendale che risulta controproducente dare la responsabilità della protezione dello stesso ad una sola persona, incaricata di risolvere la questione.
E’ necessario piuttosto dare vita ad una squadra “interdisciplinare”: è il gruppo delle risorse umane e le autorità specializzate in questo tipo di crimini che si rivelano essere la soluzione migliore. Quando un attacco è in corso, la velocità è la base del successo nel difendere e solo un network di specialisti ben preparato sarà in grado di affrontare il problema con velocità ed il massimo della pulizia.
Una buona squadra potrebbe essere composta dal responsabile IT, da un manager, dai collaboratori più stretti del licenziato e da un esperto di sicurezza informatica, magari assunto per il caso. Create una squadra di 5/6 persone, non di più.
Stabilisci che cosa bisogna proteggere
Quando si ha a che fare con informazioni aziendali importanti, definite Critical Business Information (CBI), per essere certi di fare un ottimo lavoro non si deve pensare di difendere “dati” o “processi”, ma considerare gli stessi come “persone”. In fin dei conti è proprio ciò che accade: quando si protegge un’azienda in realtà ci si prende cura del potenziale cliente finale che utilizzerà quello specifico prodotto.
Un concetto valido per qualsiasi tipo di produzione e qualsiasi tipologia di approccio difensivo che deve far parte della routine aziendale. Un buon ragionamento potrebbe essere: “Dobbiamo proteggere il nostro amministratore delegato e la privacy dei suoi familiari, il dirigente che ha assunto l’ex collaboratore e i nostri fornitori con cui il licenziato era in contatto”.
In questo modo capire automaticamente che cosa dovete proteggere: il pc dell’amministratore, il suo smartphone, gli account social della famiglia. E ancora: il conto Paypal del dirigente e il tablet dove sono registrate le consegne dei fornitori”. Pensare al “Chi”, vi aiuterà a capire immediatamente “Cosa” dovete difendere.
Conoscere la collocazione fisica e virtuale del sistema da proteggere è basilare.
Identifica dove si trovano i dispositivi a rischio
Proteggere le informazioni riservate in una azienda significa non solo conoscerne il funzionamento e la struttura ma anche l’esatta posizione, virtuale e fisica, all’interno del proprio sistema. Questo consente di poter approcciare qualsiasi problema con maggiore facilità anche se, è doveroso sottolineare, spesso il processo è molto più difficile quando ad essere presa in considerazione è una grande società con molte sedi rispetto ad un’azienda più piccola.
In ogni caso tale conoscenza è basilare per capire quanto e come le proprie informazioni siano esposte al pericolo: basta un piccolo errore e documenti di vitale importanza possono essere disponibili alla consultazione di personale non autorizzato a visionarli.
La protezione passa in questo caso anche attraverso una collaborazione molto stretta tra il team che si occupa della sicurezza virtuale della risorsa e la squadra di lavoro adibita alla protezione fisica della struttura: non si può escludere che un dipendente deluso possa trovare il modo di mettere a repentaglio la sicurezza dell’azienda attraverso una filiale vicina a dove abita.
Una volta che avrete una squadra di esperti, consapevoli di chi bisogna proteggere, di cosa bisogna difendere e di dove si trovano i terminali da mettere in sicurezza, sarete nelle condizioni di reagire adeguatamente e di passare all’atto pratico. Cambio delle password, dei conti correnti, degli accessi a gestionali e archivi.
Accorgersi prima di un dipendente potenzialmente pericoloso
Ovviamente, la prevenzione è l’arma migliore. Proteggere le informazioni aziendali in generale, è palese, è un lavoro che deve essere portato avanti in squadra, attraverso la messa a punto di un network importante in grado di funzionare in modo adeguato. Questo perché non si ha mai la certezza della tipologia di problema che si potrà affrontare. Si è fatto l’esempio del collaboratore licenziato e scontento che potrebbe tentare di rivalersi sull’azienda sfruttandone le falle.
In questo caso qualsiasi dispositivo in linea e qualsiasi uso dei computer aziendali differente da quelli stabiliti dai protocolli può inficiare l’intero sistema, mettendolo alla mercé di malintenzionati e di gravi perdite. Comprendere quali possano essere le risorse umane delle quali fidarsi e quelle delle quali avere paura non è semplice.
La chiave per anticipare il problema sta nell’avere il controllo delle informazioni: queste devono essere gestite secondo la legge e da risorse umane non solo in grado di lavorare virtualmente in maniera etica ma che siano affidabili in termini di mantenimento degli alti standard di sicurezza.
Per questo motivo, per mantenere alta la protezione di informazioni sensibili, iniziare con una selezione scrupolosa del personale diventa basilare.
Le risorse dedicate alla sicurezza informatica devono essere selezionate in maniera molto scrupolosa.
Lo stesso deve essere preparato, sapere come agire ed essere motivato al punto giusto: il coinvolgimento nella sicurezza deve essere vissuto come personale e nessuna capacità mai essere data per scontata.
Devono essere messe a punto delle regole pratiche, che diano la possibilità ai reparti dedicati dell’azienda di verificare periodicamente non solo che la preparazione dei propri dipendenti sia adeguata, ma anche che il loro comportamento rimanga ideale e costante nel tempo. Qualsiasi condotta sospetta (ad esempio un cambio di password improvviso e non giustificato da parte di un dipendente) deve poter essere scoperta e approcciata nell’immediato con il supporto di mezzi adeguati.
La dirigenza dell’azienda dovrebbe prevedere degli standard ben precisi da rispettare per poter lavorare con informazioni di tale importanza che possano essere applicati non solo sulla condotta lavorativa del personale che lavora in sede, ma anche dei dipendenti che operano in filiali.
Se il problema sicurezza viene affrontato in maniera errata da parte dei responsabili interni i protocolli rischiano di saltare, le risorse ad esse dedicate potrebbero non funzionare al 100% nel loro ruolo ed in generale si potrebbe arrivare non solo una perdita di dati ma anche alla potenziale effrazione di leggi a propria insaputa.
Un programma “difensivo” di qualità, basato su un network di risorse ben strutturate può fare la differenza, portando ad un funzionamento migliore dell’azienda.
Prevedere i crimini prima che vengano compiuti è il sogno di ogni poliziotto. E in realtà esistono i Crime Predicting Software che si occupano di raccogliere e analizzare i dati sui crimini del passato, per predire quelli nuovi e giocare di anticipo. Una soluzione fantascientifica che ci fa sentire in un nuovo mondo.
Ma… quando alcune previsioni dei software vengono azzeccate anche da persone comuni, l’entusiasmo cala.
La sicurezza della popolazione, è sempre stata garantita dalla polizia, che ha fatto affidamento sul proprio istinto e sui dati a sua disposizione per perseguire i crimini, ma che ora deve fare i conti con risorse sempre più limitate poiché la lotta alla criminalità e l’aumento della violenza rendono l’operato della polizia ogni giorno più difficile.
Nati alla fine degli anni ’80 negli Stati Uniti, i Crime Predicting Software sono stati sviluppati con l’intento di fornire un supporto scientifico all’indagine criminologica, creando delle vere e proprie previsioni sui crimini del futuro.
Affidarsi a software dedicati che si occupano della rilevazione, dell’analisi e dell’interpretazione di tali dati, appare davvero come una ottima soluzione per rimanere al passo con i tempi e, addirittura, anticiparli.
I software che prevedono i crimini. La raccolta dati e la mappatura
Dalla mappatura dei dati alla previsione dei crimini: così lavora un Crime Prediction Software
Analizzando il funzionamento nel dettaglio, i dati raccolti dal lavoro quotidiano del dipartimento di polizia vengono catalogati in sistemi di gestione delle banche dati che associano informazioni geografiche (es. latitudine e longitudine) con indirizzi e aree di segnalazione della polizia e memorizzano e gestiscono chiamate di servizio, arresti e altri dati potenzialmente mappabili, comuni alla maggior parte dei dipartimenti di medie e grandi dimensioni.
Garantire la qualità dei dati è fondamentale. Se non sono completi, accurati o tempestivi, viene meno questo sistema di localizzazione.
Una volta messi insieme e resi disponibili per l’analisi infatti, questi volumi di dati sono fondamentali per comprendere non solo ciò che è accaduto in passato ma, sulla base di tali modelli, ciò che si svilupperà, potenzialmente, in futuro.
La migliore organizzazione e i modelli di previsione consentono alle agenzie di anticipare incidenti, individuare profili criminali, ridurre i tassi di criminalità e ottimizzare l’utilizzo delle risorse.
Basandosi su episodi precedenti, profili, mappe e tipologie, oltre a fattori quali eventi meteorologici o giorni festivi e di paga, i funzionari di polizia possono individuare aree tipicamente frequentate da criminali violenti.
Vengono stilati identikit per identificare somiglianze con delinquenti noti e individuare le condizioni scatenanti i crimini violenti, per prevedere quando e dove questi crimini potrebbero verificarsi in futuro, nonché determinare la probabilità di recidiva.
Così la polizia gioca d’anticipo
Per prevedere i crimini, i software appositi uniscono dati, età, zone geografiche e scadenze (come i giorni di paga o le festività) per creare una reportistica
Una volta che le informazioni sono state elaborate e diventano disponibili, questi software permettono agli agenti di polizia di accedere a informazioni accuratamente calcolate che consentono di monitorare in anticipo le attività criminali, prevedere la probabilità di incidenti.
Ma non solo: anche distribuire efficacemente le risorse e risolvere i casi più velocemente, ovvero ampliare il proprio campo d’azione in maniera più intelligente, assicurandosi che nessuno sforzo venga sprecato attraverso un uso migliore delle informazioni che vengono generate e memorizzate.
Le informazioni più affidabili consentono alle forze dell’ordine di migliorare le indagini, la pianificazione delle proprie risorse, la gestione dei casi, le operazioni e l’applicazione. Con questa intuizione, la prevenzione del crimine diventa una scienza.
I dubbi degli studiosi
Sarebbe tutto bello, se non fosse che recenti studi eseguiti al Darmouth College, hanno dimostrato come software ampiamente utilizzati potrebbero essere accurati nel predire comportamenti criminali tanto quanto persone senza alcuna esperienza in materia.
L’analisi ha mostrato che i non addetti ai lavori che hanno risposto a un sondaggio online, si sono comportati esattamente come il Crime Predicting Software COMPAS(Correctional Offender Management Profiling for Alternative Sanctions) utilizzato dai tribunali per aiutare a determinare il rischio di recidiva, sollevando il problema sulla effettiva utilità di questi strumenti.
Il documento di ricerca della Darmouth mette a confronto il software commerciale COMPAS e alcuni volontari individuati tramite il Marketplace online Amazon Mechanical Turk, per analizzare quale approccio è più accurato ed equo nel giudicare la possibilità di recidiva, intesa come l’atto di commettere un reato, anche minore, entro due anni dall’ultimo arresto di un imputato.
Uno studio mette in dubbio la loro efficacia: anche persone senza esperienza riescono ad azzeccare le previsioni
Ai gruppi di lavoratori sono state sottoposte brevi descrizioni circa il sesso, l’età e la precedente storia criminale di un imputato.
I risultati umani sono stati quindi confrontati con i risultati del sistema COMPAS, che utilizza 137 identikit variabili per ciascun individuo.
Risultati dello studio: anche persone senza esperienza ci azzeccano
Con meno informazioni rispetto a quelle del COMPAS, 7 anziché 137, i risultati emersi sono risultati pressoché simili: 67% dei casi presentati al gruppo di lavoratori contro il 65, 2% del COMPAS. I partecipanti allo studio e il COMPAS erano d’accordo sul 69,2% dei 1000 imputati nel predire chi avrebbe ripetuto i crimini.
Lo studio dimostra addirittura che, sebbene il COMPAS si serva di oltre un centinaio di informazioni, lo stesso livello di accuratezza può essere ottenuto con due sole variabili: l’età dell’imputato e il numero di condanne precedenti.
Secondo lo studio, la questione della previsione accurata della recidiva non è limitata al COMPAS ma è stato rilevato che otto dei nove programmi software sottoposti ad ulteriori esami non sono riusciti a fare previsioni accurate, e le abilità di essere umani senza esperienza erano perlomeno pari a quelle dei software.
Infine, nonostante non sia tecnicamente rilevante, quando è stata presa in considerazione la razza, la ricerca ha scoperto che i risultati di entrambi gli intervistati umani e del software hanno mostrato notevoli disparità nel modo in cui vengono giudicati gli imputati in base al colore della pelle.
"Utilizziamo i cookie per personalizzare contenuti ed annunci, per fornire funzionalità dei social media e per analizzare il nostro traffico. Condividiamo inoltre informazioni sul modo in cui utilizza il nostro sito con i nostri partner che si occupano di analisi dei dati web, pubblicità e social media, i quali potrebbero combinarle con altre informazioni che ha fornito loro o che hanno raccolto dal suo utilizzo dei loro servizi.
Cliccando su “Accetta tutti”, acconsenti all'uso di tutti i cookie. Cliccando su “Rifiuta”, continui la navigazione senza i cookie ad eccezione di quelli tecnici. Per maggiori informazioni o per personalizzare le tue preferenze, clicca su “Gestisci preferenze”."
Questo sito web utilizza i cookie.
I siti web utilizzano i cookie per migliorare le funzionalità e personalizzare la tua esperienza. Puoi gestire le tue preferenze, ma tieni presente che bloccare alcuni tipi di cookie potrebbe avere un impatto sulle prestazioni del sito e sui servizi offerti.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_logged_in
Used to store logged-in users.
Persistent
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
_gac_
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
X Pixel enables businesses to track user interactions and optimize ad performance on the X platform effectively.
Our Website uses X buttons to allow our visitors to follow our promotional X feeds, and sometimes embed feeds on our Website.
2 years
guest_id
This cookie is set by X to identify and track the website visitor. Registers if a users is signed in the X platform and collects information about ad preferences.
2 years
personalization_id
Unique value with which users can be identified by X. Collected information is used to be personalize X services, including X trends, stories, ads and suggestions.
2 years
Per maggiori informazioni, consulta la nostra https://www.alground.com/site/privacy-e-cookie/